MLJ Cheatsheet
Starting an interactive MLJ session
julia> using MLJ
julia> MLJ_VERSION # version of MLJ for this cheatsheet
v"0.12.1"Model search and code loading
info("PCA") retrieves registry metadata for the model called "PCA"
info("RidgeRegressor", pkg="MultivariateStats") retrieves metadata for "RidgeRegresssor", which is provided by multiple packages
models() lists metadata of every registered model.
models(x -> x.is_supervised && x.is_pure_julia) lists all supervised models written in pure julia.
models(matching(X)) lists all unsupervised models compatible with input X.
models(matching(X, y)) lists all supervised models compatible with input/target X/y.
With additional conditions:
models() do model
matching(model, X, y) &&
model.prediction_type == :probabilistic &&
model.is_pure_julia
endtree = @load DecisionTreeClassifier to load code and instantiate "DecisionTreeClassifier" model
tree2 = DecisionTreeClassifier(max_depth=2) instantiates a model type already in scope
ridge = @load RidgeRegressor pkg=MultivariateStats loads and instantiates a model provided by multiple packages
Scitypes and coercion
scitype(x) is the scientific type of x. For example scitype(2.4) == Continuous
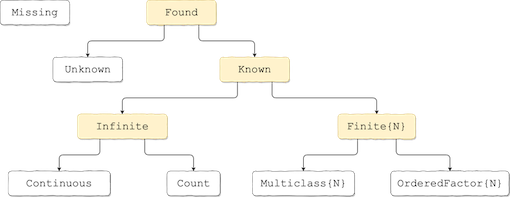
| type | scitype |
|---|---|
AbstractFloat | Continuous |
Integer | Count |
CategoricalValue and CategoricalString | Multiclass or OrderedFactor |
Figure and Table for common scalar scitypes
Use schema(X) to get the column scitypes of a table X
coerce(y, Multiclass) attempts coercion of all elements of y into scitype Multiclass
coerce(X, :x1 => Continuous, :x2 => OrderedFactor) to coerce columns :x1 and :x2 of table X.
coerce(X, Count => Continuous) to coerce all columns with Count scitype to Continuous.
Ingesting data
Splitting any table into target and input (note semicolon):
using RDatasets
channing = dataset("boot", "channing")
y, X = unpack(channing,
==(:Exit), # y is the :Exit column
!=(:Time); # X is the rest, except :Time
:Exit=>Continuous, # correcting wrong scitypes (optional)
:Entry=>Continuous,
:Cens=>Multiclass)Warning. Before julia 1.2 use col -> col != :Time insead of !=(:Time).
Splitting row indices into train/validation/test:
train, valid, test = partition(eachindex(y), 0.7, 0.2, shuffle=true, rng=1234) for 70:20:10 ratio
For a stratified split:
train, test = partition(eachindex(y), 0.8, stratify=y)
Getting data from OpenML:
table = openML.load(91)
Creating synthetic classification data:
X, y = make_blobs(100, 2) (also: make_moons, make_circles)
Creating synthetic regression data:
X, y = make_regression(100, 2)
Machine construction
Supervised case:
model = KNNRegressor(K=1) and mach = machine(model, X, y)
Unsupervised case:
model = OneHotEncoder() and mach = machine(model, X)
Fitting
fit!(mach, rows=1:100, verbosity=1, force=false)
Prediction
Supervised case: predict(mach, Xnew) or predict(mach, rows=1:100)
Similarly, for probabilistic models: predict_mode, predict_mean and predict_median.
Unsupervised case: transform(mach, rows=1:100) or inverse_transform(mach, rows), etc.
Inspecting objects
@more gets detail on last object in REPL
params(model) gets nested-tuple of all hyperparameters, even nested ones
info(ConstantRegressor()), info("PCA"), info("RidgeRegressor", pkg="MultivariateStats") gets all properties (aka traits) of registered models
info(rms) gets all properties of a performance measure
schema(X) get column names, types and scitypes, and nrows, of a table X
scitype(X) gets scientific type of a table
fitted_params(mach) gets learned parameters of fitted machine
report(mach) gets other training results (e.g. feature rankings)
Saving and retrieving machines
MLJ.save("trained_for_five_days.jlso", mach) to save machine mach
predict_only_mach = machine("trained_for_five_days.jlso") to deserialize.
Performance estimation
evaluate(model, X, y, resampling=CV(), measure=rms, operation=predict, weights=..., verbosity=1)
evaluate!(mach, resampling=Holdout(), measure=[rms, mav], operation=predict, weights=..., verbosity=1)
evaluate!(mach, resampling=[(fold1, fold2), (fold2, fold1)], measure=rms)
Resampling strategies (resampling=...)
Holdout(fraction_train=0.7, rng=1234) for simple holdout
CV(nfolds=6, rng=1234) for cross-validation
StratifiedCV(nfolds=6, rng=1234) for stratified cross-validation
or a list of pairs of row indices:
[(train1, eval1), (train2, eval2), ... (traink, evalk)]
Tuning
Tuning model wrapper
tuned_model = TunedModel(model=…, tuning=RandomSearch(), resampling=Holdout(), measure=…, operation=predict, range=…)
Ranges for tuning (range=...)
If r = range(KNNRegressor(), :K, lower=1, upper = 20, scale=:log)
then Grid() search uses iterator(r, 6) == [1, 2, 3, 6, 11, 20].
lower=-Inf and upper=Inf are allowed.
Non-numeric ranges: r = range(model, :parameter, values=…)
Nested ranges: Use dot syntax, as in r = range(EnsembleModel(atom=tree), :(atom.max_depth), ...)
Can specify multiple ranges, as in range=[r1, r2, r3]. For more range options do ?Grid or ?RandomSearch
Tuning strategies
Grid(resolution=10) or Grid(goal=50) for basic grid search
RandomSearch(rng=1234) for basic random search
Learning curves
For generating plot of performance against parameter specified by range:
curve = learning_curve(mach, resolution=30, resampling=Holdout(), measure=…, operation=predict, range=…, n=1)
curve = learning_curve(model, X, y, resolution=30, resampling=Holdout(), measure=…, operation=predict, range=…, n=1)
If using Plots.jl:
plot(curve.parameter_values, curve.measurements, xlab=curve.parameter_name, xscale=curve.parameter_scale)
Performance measures (metrics)
area_under_curve, accuracy, balanced_accuracy, cross_entropy, FScore, false_discovery_rate, false_negative, false_negative_rate, false_positive, false_positive_rate, l1, l2, mae, matthews_correlation, misclassification_rate, negative_predictive_value, positive_predictive_value, rms, rmsl, rmslp1, rmsp, true_negative, true_negative_rate, true_positive, true_positive_rate, BrierScore(), confusion_matrix
Available after doing using LossFunctions:
DWDMarginLoss(), ExpLoss(), L1HingeLoss(), L2HingeLoss(), L2MarginLoss(), LogitMarginLoss(), ModifiedHuberLoss(), PerceptronLoss(), SigmoidLoss(), SmoothedL1HingeLoss(), ZeroOneLoss(), HuberLoss(), L1EpsilonInsLoss(), L2EpsilonInsLoss(), LPDistLoss(), LogitDistLoss(), PeriodicLoss(), QuantileLoss()
measures() to get full list
info(rms) to list properties (aka traits) of the rms measure
Transformers
Built-ins include: Standardizer, OneHotEncoder, UnivariateBoxCoxTransformer, FeatureSelector, FillImputer, UnivariateDiscretizer, UnivariateStandardizer, ContinuousEncoder
Externals include: PCA (in MultivariateStats), KMeans, KMedoids (in Clustering).
models(m -> !m.is_supervised) to get full list
Ensemble model wrapper
EnsembleModel(atom=…, weights=Float64[], bagging_fraction=0.8, rng=GLOBAL_RNG, n=100, parallel=true, out_of_bag_measure=[])
Pipelines
With deterministic (point) predictions:
pipe = @pipeline OneHotEncoder KNNRegressor(K=3) target=UnivariateStandardizer
pipe = @pipeline OneHotEncoder KNNRegressor(K=3) target=v->log.(V) inverse=v->exp.(v))
Unsupervised:
pipe = @pipeline Standardizer OneHotEncoder
Define a supervised learning network:
Xs = source(X) ys = source(y)
... define further nodal machines and nodes ...
yhat = predict(knn_machine, W, ys) (final node)
Exporting a learning network as stand-alone model:
Supervised, with final node yhat returning point-predictions:
@from_network machine(Deterministic(), Xs, ys; predict=yhat) begin
mutable struct Composite
reducer=network_pca
regressor=network_knn
endHere network_pca and network_knn are models appearing in the learning network.
Supervised, with yhat final node returning probabilistic predictions:
@from_network machine(Probabilistic(), Xs, ys; predict=yhat) begin
mutable struct Composite
reducer=network_pca
classifier=network_tree
endUnsupervised, with final node Xout:
@from_network machine(Unsupervised(), Xs; transform=Xout) begin
mutable struct Composite
reducer1=network_pca
reducer2=clusterer
end
end