Investigating the link between infections and hospitalizations using COVID-19 data in England for 2020-2021 and Bayesian inference.
Reviewers
Helen Duncan, Alan Turing Institute
Christina Last, Alan Turing Institute
Luke Hare, Alan Turing Institute
Introduction
On 28 June, 2021, newly installed Health Secretary Sajid Javid announced that the COVID-19 Vaccine Programme in the UK had severed the link between infection and severe disease, hospitalization, and death (see here for the speech made to parliament on this topic). Although cases were rising quickly at the time due to the spread of the Delta variant, this was not leading to as strong a rise in hospital admissions and deaths when compared to the earlier waves of the disease.
However, one problem that had cropped up in the COVID-19 pandemic is that exponential rises in cases, combined with some strong inertia in the causal chains that lead from infection to hospital admission, can obscure a crisis situation that can quickly become much, much worse. The delay between infection and hospital admission can last for a few weeks, so it may be that we just had not waited long enough to see the effect of cases on the hospital admissions at the time of the speech. This story examines a method for analyzing the COVID-19 data in England for 2020-2021 and accounting for uncertainty by applying Bayesian inference to the problem.
Data
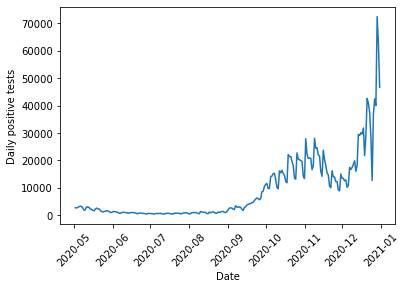
The UK has a COVID-19 data website with a public API that allows us to examine daily counts for COVID-19 tests, hospital admissions, deaths, and other statistics surrounding the pandemic. We are principally interested in determining how positive tests collected on a particular date lead to hospital admissions some time later. Because testing was not always consistent in the early days of the pandemic, we will focus our analysis on the fall “second wave” starting in July 2020, using test data starting from May 2020. While the May 2020 data likely includes a time period where widespread testing was not available, we do this to give our model a fixed window of 60 days to link hospital admissions to tests on any of the previous days in the window to ensure that we fully account for the possibility of a long delay between tests and hospital admission.
Similarly, since the first vaccine doses were given in late December 2020, we cut off our period of analysis for fitting the model at 31 December, 2020, to ensure that we fit the model to a time period where we can be confident that no widespread vaccines had been given. We will use this time period to fit the model parameters, and then make predictions on the spring/summer 2021 wave using the model parameters derived from the fall 2020 data.
First, we can look at the COVID test data for England for this time period:
%matplotlib inlineimport pandasimport matplotlib.pyplot as pltdef get_data(query_type, start, end):"Queries UK Covid Data API for a particular type of data and returns data queried during a specific time frame" url ='https://coronavirus.data.gov.uk/api/v1/data?filters=areaType=nation&structure=%7B%22areaType%22:%22areaType%22,%22areaName%22:%22areaName%22,%22areaCode%22:%22areaCode%22,%22date%22:%22date%22,%22query_type%22:%22query_type%22%7D&format=csv' new_url = url.replace("query_type", query_type) df = pandas.read_csv(new_url) df["date"] = pandas.to_datetime(df["date"]) query_string ='areaName == "England" & date >= "{}" & date <= "{}"'.format(start, end)return df.query(query_string)cases_str ="newCasesBySpecimenDate"cases = get_data(cases_str, "2020-05-02", "2020-12-31")plt.plot(cases["date"], cases[cases_str])plt.xlabel("Date")plt.ylabel("Daily positive tests")plt.xticks(rotation=45);
To examine hospital admissions, we need to develop a model that predicts two things: how many hospital admissions to expect given a number of positive COVID tests, and when those hospital admissions occur. One simple way we might do this is via the following:
All positive tests have a fixed probability \(\psi\) of causing a hospital admission at some later date. This is all that is required to determine how many hospital admissions occur given a number of positive tests.
For those that will be admitted to hospital, we then need to determine when the person will go into hospital. We use the following model to determine the date:
Every day, a COVID-19 patient that will eventually require hospitalization has a fixed probability \(p\) of their condition worsening.
Once their condition has worsened \(k\) times, they are admitted to hospital.
This process follows a negative binomial distribution, shifted by \(k\) days. An equivalent way to view this is to say that the date of hospital admission follows a multinomial distribution, with the multinomial probabilities following the PMF of a negative binomial distribution, shifted by \(k\) days.
A negative binomial distribution describes the number of successful Bernoulli trials expected before we obtain a fixed number of failures. Note that we need to shift this distribution because we care about the total number of trials before we reach the fixed number of failures, rather than the number of successes.
Once we can predict how many hospital admissions to expect and when they occur, we just need to provide the model with the number of positive tests on each day, and the model will output a prediction of the number of hospital admissions on each day. This can then be compared with the data to estimate the values of \(\psi\), \(p\), and \(k\).
The model is implemented below. Note that since the UK COVID API returns data with the most recent dates first, while our simulation goes forward in time, we need to reverse the cases to feed it into the function that simulates hospitalizations. Note also that we do a few checks of the admission probabilities before they are fed into the multinomial distribution – this is because the outputs of the admission probabilities sum to greater than one on occasion due to rounding errors, and sometimes we might have accidentally put in a bad number for \(k\) that returns NaN values so we would like to prevent these situations from crashing our simulation.
import numpy as npfrom scipy.stats import binom, nbinom, multinomialdef reverse_df_data(df, column):return np.array(df[column], dtype=np.int64)[::-1]def simulate_hospital_admissions(cases, psi, k, p):"Run a random forward simulation of the hospitalizations given cases and the model parameters" daily_hospital_admissions = binom.rvs(n=cases, p=np.broadcast_to(psi, (len(cases),)), size=(len(cases),)) window =60 dates = np.arange(0, window, 1, dtype=np.int64) admission_probs = nbinom.pmf(dates, loc=k, n=k, p=p)# Run a few checks on admission_probs to avoid issues with multinomial samplingif np.sum(admission_probs) >1.: admission_probs = admission_probs/(1.+1.e-10)if np.any(np.isnan(admission_probs)):return np.zeros(len(cases)-window, dtype=np.int64) admissions = np.zeros(len(cases)+window)for i inrange(len(daily_hospital_admissions)): admit_samples = multinomial.rvs(n=daily_hospital_admissions[i], p=admission_probs, size=1)[0] admissions[i:i+window] += admit_samplesreturn admissions[window:-window]case_array = reverse_df_data(cases, cases_str)admissions_array = simulate_hospital_admissions(case_array, 0.1, 4, 0.1)plt.plot(admissions["date"][::-1], admissions_array)plt.xlabel("Date")plt.ylabel("Simulated daily hospital admissions")plt.xticks(rotation=45);
If you try simulating different choices of \(\psi\), \(p\) and \(k\), you can see that the parameters that control the timing of admissions does have an effect on the overall size and shape of the peak (or peaks). Thus, we need to find a way to use the actual hospitalization data to fit reasonable values for these simulation parameters.
Bayesian Inference
To fit the model and account for uncertainty, we will turn to Bayesian Inference. Bayesian Inference treats our model parameters \(\theta = (\psi, p, k)\) as uncertain and thus described by a probability distribution. We wish to compute the posterior distribution of our parameters conditioned on the observed hospitalization data from the fall 2020 \(y\), written \(p(\theta|y)\). To compute this, we use Bayes’ rule
\[p(\theta|y)=\frac{p(y|\theta)p(\theta)}{p(y)}\]
which relates the posterior to the likelihood \(p(y|\theta)\), or the probability that a given choice of parameters would have produced the data, our prior beliefs about reasonable parameter values \(p(\theta)\), and the evidence \(p(y)\), which is the probability of getting the data given all possible models. In most cases, computing the evidence is not feasible, so we resort to drawing samples from the posterior distribution rather than computing the distribution analytically.
Prior
We need to specify our initial beliefs about what we expect might be reasonable model parameters. Based on previous reporting on the pandemic, we expect a relatively small fraction of positive tests to result in hospital admissions. We can quantify this through a Beta distribution, a flexible distribution well suited for modeling parameters that are constrained between 0 and 1. Beta distributions have two shape parameters \(a\) and \(b\) (or \(\alpha\) and \(\beta\)) that control where the distribution has highest density. We want our priors to be skewed towards small numbers, so we will choose \(a=0.5\) and \(b=2\), which puts most of the distribution mass at smaller values.
For \(k\) and \(p\), we might want to consider information that hospital admissions usually occur a week or two after contracting the disease. However, there are two ways our model might express this: \(k\) and \(p\) could both be large, meaning that the patient has a high probability of their conditions worsening a little bit each day, eventually leading to a (predictable) hospital admission a large number of days later. Alternatively, \(p\) and \(k\) might both be small. This would describe the situation where the person testing positive has a low chance of their symptoms getting significantly worse every day, but when it does get worse they must be hospitalized quickly. This will lead to more variability in the exact hospitalization date. We have no reason to prefer either possibility, nor would we like to exclude either possibility, so we will use uniform priors for \(k\) and \(p\) (a Discrete Uniform distribution for \(k\) between 1 and 20 and a Beta distribution with \(a=1\) and \(b=1\) for \(p\)).
Finally, we should note that the model for determining when a patient goes into hospital is probably not a very realistic description of how a COVID-19 infection proceeds. Rather, we should think more about the two end member cases described above as ways of capturing exactly when, on average, patients need to be admitted to hospital, and the variability in when that occurs. Looking at the values that best fit the data thus tells us more about the type of model that tends to fit the data, rather than providing actual clinical insight into the disease.
Likelihood
The data for this model is a time series of hospital admissions that is a superposition of many Multinomial distributions. The likelihood for this model unfortunately does not exist in closed form. However, we can easily run a forward simulation of the approach by sampling from the appropriate probability distributions, so we will resort to a method known as Approximate Bayesian Computation (ABC) to approximate the likelihood.
Rather than requiring that the forward model produce exactly the same set of hospital admissions as is seen in the data (which is unlikely due to the fact that we are performing a single random sample when we run the forward simulation), we will instead try to find a model that is fairly close to the data. We use a Gaussian measure of dissimilarity, which penalizes models that show a large difference between the real data and the model predictions. The Gaussian measure depends on an additional parameter \(\epsilon\), which can be thought of as a tolerance parameter that sets the scale for how much to penalize the difference between the real and simulated data.
We use \(\epsilon=500\) here due to the number of daily hospitalizations being in the thousands at the peak, or in other words we want to penalize models that differ by more than around 500 between the real and simulated data. However, some experimenting with values from 10 to 2000 has shown that the exact results are not too sensitive to the choice of this parameter so we can be confident that the results do not depend too much on this choice.
Sequential Monte Carlo Sampling
As discussed above, rather than compute the posterior directly, we will draw samples from it. To do so, we will use a technique known as Sequential Monte Carlo (SMC) sampling, or, in some other contexts, Particle Markov Chain Monte Carlo. SMC is a method for sampling from an unknown distribution (the posterior) by instead sampling from a known distribution (the prior) and then resampling based on weights determined from the computed likelihood \(\times\) prior for each sample. The higher the weight of a particular sample, the higher the probability it will be re-sampled and remain in the set of samples taken at the next step. Thus, over time, the samples where the posterior is highest will be repeatedly passed on to the next step, while those where the posterior is lower will be removed.
This resampling technique works best if the two distributions are similar. Because we expect the prior and posterior to be quite different, SMC gradually tunes between the prior and posterior by resampling from \(q \propto p(y|\theta)^\beta p(\theta)\) at each step, where \(\beta\) varies from 0 to 1. This ensures that the two distributions are reasonably similar at each step and the resampling technique will be accurate.
In addition to resampling, which ensures that good samples are likely to show up in successive steps, SMC also perturbs the samples at each step using a Markov Chain Monte Carlo random walk to ensure that the method explores the regions surrounding good samples. Both the tempering and exploration can be tuned adaptively based on the results of the sampling to try and optimize the number of steps needed to move between the prior and the posterior. This helps to balance accuracy of the sampling with the computational cost.
Implementation
Below, I implement this model and draw samples from it using the PyMC3 library. The Simulation class in PyMC3 allows us to do ABC inference and draw the samples using SMC without having the explicit likelihood implemented in the library.
Note also that I need to bind the array of cases to the simulation function, which I do so using the partial function in the functools module – this is because the PyMC3 Simulation class requires that the only parameters that are passed to the simulation be the model parameters that we are trying to estimate. Since the actual cases are known, and are not estimated, we need to fix that value of the input.
Finally, PyMC3 by default draws multiple sets of samples based on the number of cores on the computer, so I set the number of chains to be 1 to give consistent results across different machines. Be aware that to draw the full set of 2000 samples, the simulations were run for roughly 10 minutes on a MacBook Pro.
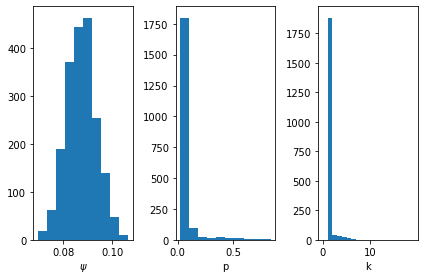
First, we can look at the posterior samples to learn about the type of model that fits the data. We see that \(\psi\) has a peak around 9%, meaning that proportion of positive tests lead to hospitalization. The distribution is fairly tight around this value, so there is not much uncertainty in this parameter.
For \(p\) and \(k\), we see that most of the samples tend to favor the low \(p\), low \(k\) model described above. As previously discussed, this is not necessarily a realistic model of how an infection evolves, but rather a way of understanding the uncertainty in when a patient goes into hospital. What is important is that there is variability in when we expect positive tests on a given day to lead to later hospitalizations.
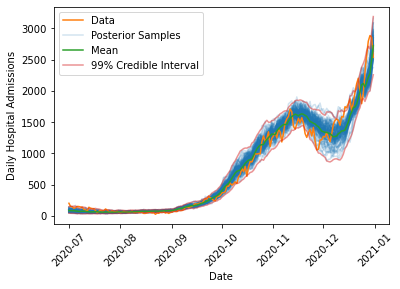
We can look at the range of simulated outcomes and compare these (along with some summary statistics) to the actual evolution in cases.
def draw_posterior_samples(cases, trace):"Draw samples from the simulation using the SMC samples" samples = []for s in trace: samples.append(simulate_hospital_admissions(cases, s["psi"], s["k"], s["p"]))return np.array(samples)def compute_posterior_statistics(samples):"Compute mean and credible intervals from posterior samples" mean = np.mean(samples, axis=0) quantile_005 = np.quantile(samples, 0.005, axis=0) quantile_995 = np.quantile(samples, 0.995, axis=0)return mean, quantile_005, quantile_995def plot_data_with_samples(cases, admissions, trace): samples = draw_posterior_samples(cases, trace) mean, quantile_005, quantile_995 = compute_posterior_statistics(samples) plt.plot(admissions["date"][::-1], samples.T[:,:100], color="C0", alpha=0.2) plt.plot(admissions["date"], admissions[admissions_str], color="C1", label="Data") plt.xlabel("Date") plt.ylabel("Daily Hospital Admissions") plt.plot([], [], color='C0', alpha=0.2, label='Posterior Samples') plt.plot(admissions["date"][::-1], mean, color="C2", label="Mean") plt.plot(admissions["date"][::-1], quantile_005, color="C3", alpha=0.5) plt.plot(admissions["date"][::-1], quantile_995, color="C3", alpha=0.5, label="99% Credible Interval") plt.legend() plt.xticks(rotation=45)plot_data_with_samples(case_array, admissions, trace)
The model is able to capture the overall dynamics of the fall 2020 wave, including the rise in admissions in October 2020, the decrease in late November 2020 due to the second national lockdown which began on 5 November, 2020, and the continued rise through Christmas 2020 when the third national lockdown came into effect on 6 January, 2021.
Interestingly, the model has difficulty capturing the timing of the decrease at the end of the second lockdown, where the actual data strays outside of the 99% interval on the posterior samples. One reason this might occur is that during the second lockdown, schools remained in session, while most other non-essential sectors of the economy were forced to close. This means that younger children probably saw a smaller decrease in their exposure to COVID than most adults (many of whom were just staying home and not going to work). This likely changed the underlying demographics of the population testing positive to skew younger. We expect fewer hospitalizations in a younger population, which might explain the more rapid drop in admissions in late November 2020 in the real data when compared to the simulations. This appears to be a consistent feature of all models that were fit to the data, suggesting this is a change in the data rather than a shortcoming of the model.
Predicting the Spring 2021 Wave
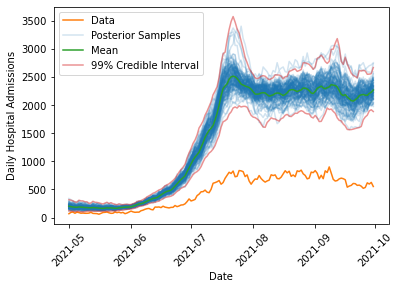
We can now query the data for the spring/summer 2021 increase in cases, and forecast what the model fit on the fall 2020 data would predict. We simulate the spring/summer 2021 wave for all sets of samples that were drawn from the posterior to determine the posterior predictive distribution, and then for each point in time we can compute credible intervals to put uncertainty bounds on the predicted hospitalizations if the spring/summer 2021 wave could be modelled with the same parameters as the fall 2020 wave:
As we can see, the model predicts substantially more hospitalization (by a factor of about 4-5) than is observed in the data, lending credence to the claim that the link between infections and hospital admissions had been weakened. Additionally, the uncertainty in the prediction is much smaller than the observed differences, suggesting that this would need to be due to some extremely rare fluke if there had not been any changes in the underlying population being exposed to COVID. Note also that the fluctuations in the number of hospital admissions predicted in summer 2021 are quite large (roughly a difference of 1000 between the lowest and highest estimates). This suggests that despite months of data on infections and hospitalizations there is still considerable uncertainty in understanding how much hospital care a population exposed to COVID will require. This should highlight the need for careful consideration of the modelling assumptions that are made in any forecast of the effect of an emerging, uncertain infectious disease on the vulnerable members of a population.
Discussion
Why might the link between infections and hospitalizations be weaker? One obvious reason is vaccination, which is what was highlighted by the Health Secretary in his announcement. While this almost certainly played a big role, we cannot necessarily attribute the entire effect to this. Why?
As mentioned above, we saw that the model had difficulty handling the data during the second national lockdown, and one possible explanation was a change in the population testing positive. Indeed, during the time period under consideration, schools were open while other parts of the economy remained under restriction, meaning that it is possible that more testing in schools could be partially responsible for this difference. Since young people received vaccines later than the elderly population during spring/summer 2021, we would expect that as time progresses, the population that tests positive should gradually skew younger, which could explain some of the reduction in hospital admissions over spring/summer 2021. However, we can potentially estimate the magnitude of this effect by looking at the November 2020 data, which shows a reduction of a few hundred hospital admissions. This is substantially smaller than the observed differences, so it is unlikely to explain the full discrepancy between the model and the data.
Given that we are confident that the data differs from the predictions, how might we account for vaccinations? One possibility is to make \(\psi\) no longer a constant, but rather a function of the single and double dose vaccination rates, possibly with a time lag to allow for immunity to build up. We might also fit three different \(\psi\) values for 0, 1, or 2 vaccine doses, though since vaccinated people are less likely than unvaccinated people to become infected, we would also need to estimate the chances of infection which is likely to be difficult. This is particularly true due to the fact that infection rates can be very locally heterogeneous, as pockets of the population with more or less vaccination coverage will see very different infection rates.
Regardless of the exact cause of this reduced hospitalization risk, the change in the data clearly shows that this wave of the pandemic differs from the previous ones. As the UK Government shifts its policies to one of learning to live with the virus, rather than one of actively suppressing it, data on infections and hospitalizations will continue to provide valuable insight into the evolution of the pandemic and should be guiding our decisions and behavior. Hopefully, this model provides an example of how this can be done with an eye for building simple, interpretable models that robustly account for uncertainty.