Graphs and Sets (Geometric Deep Learning)
Why are graphs/sets a useful blueprint for “geometric” deep learning?
Both a graph and a set provide a structure that is easy to analyze:
- Domain is discrete (nodes or nodes + edges)
- Minimal geometric assumptions [there was a comment on “resistance to permutations” that I didn’t get]
What kind of data is graph-like?
Basically anything! Fun example: tube map 😊
Also google maps: optimal route from A —> B probably goes through a graph neural network.
First step: graphs without edges (sets)
j Useful for point-cloud like structures, unordered collections of objects. We can begin by defining a set of \(n\) nodes, each with a feature vector \(\mathbf{x}_i\) of length \(v\), giving us the \(n \times v\) feature matrix \(\mathbf{X}\), where every row is a set of features for one node:
\[ \mathbf{X} = \begin{bmatrix} \mathbf{x}_{1} \\ \mathbf{x}_{2} \\ \vdots \\ \mathbf{x}_{n} \end{bmatrix} ~. \]
Ah, but wait: I’ve chosen to number the nodes 1 through \(n\) right? That means I’ve defined an ordering! We need to make sure that the result of any calculation involving \(\mathbf{}\)\(\mathbf{X}\) is invariant to the ordering of the nodes, since we want to treat this as an unordered collection.
Another way of putting this is that we want the result of applying our calculation to be equal for all possible orderings of \(\mathbf{X}\):
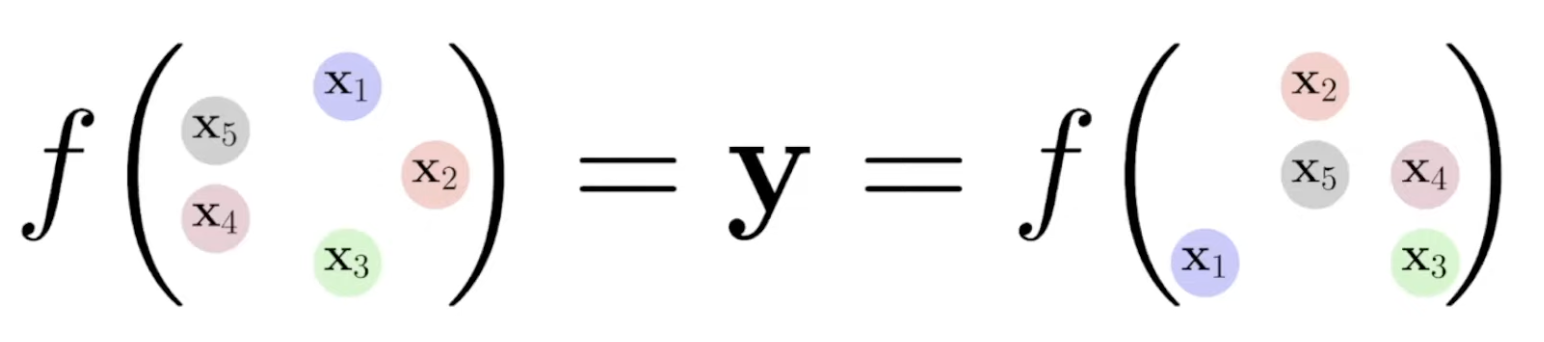
Why are graphs/sets a useful blueprint for “geometric” deep learning?
Both a graph and a set provide a structure that is easy to analyze:
- Domain is discrete (nodes or nodes + edges)
- Minimal geometric assumptions [there was a comment on “resistance to permutations” that I didn’t get]
What kind of data is graph-like?
Basically anything! Fun example: tube map 😊
Also google maps: optimal route from A —> B probably goes through a graph neural network.
First step: graphs without edges (sets)
j Useful for point-cloud like structures, unordered collections of objects. We can begin by defining a set of \(n\) nodes, each with a feature vector \(\mathbf{x}_i\) of length \(v\), giving us the \(n \times v\) feature matrix \(\mathbf{X}\), where every row is a set of features for one node:
\[ \mathbf{X} = \begin{bmatrix} \mathbf{x}_{1} \\ \mathbf{x}_{2} \\ \vdots \\ \mathbf{x}_{n} \end{bmatrix} ~. \]
Ah, but wait: I’ve chosen to number the nodes 1 through \(n\) right? That means I’ve defined an ordering! We need to make sure that the result of any calculation involving \(\mathbf{}\)\(\mathbf{X}\) is invariant to the ordering of the nodes, since we want to treat this as an unordered collection.
Another way of putting this is that we want the result of applying our calculation to be equal for all possible orderings of \(\mathbf{X}\):
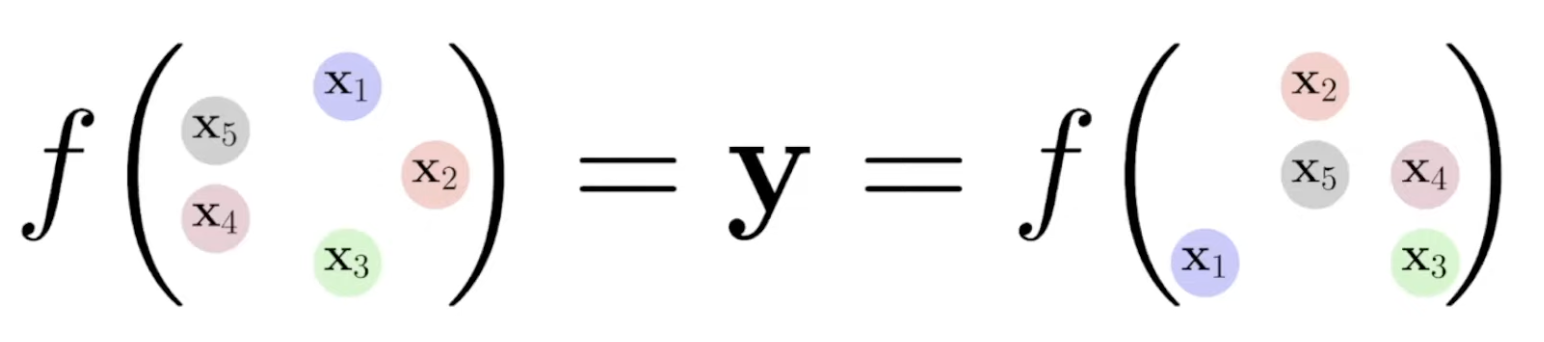
This is a function \(f\) applied to two different orderings, or permutations of nodes, and we’re requiring that they’re equal in output. To permute the nodes is to change their order; we want this condition of equality to hold over all possible permutations.
We can write permutations of \(\mathbf{X}\) as the product of \(\mathbf{X}\) with some permutation matrix \(\mathbf{P}\), which is square in the feature dimension \(v\), and has exactly one 1 in each row and column. The only result of applying \(\mathbf{P}\) is the reordering of the feature vector order. Example:
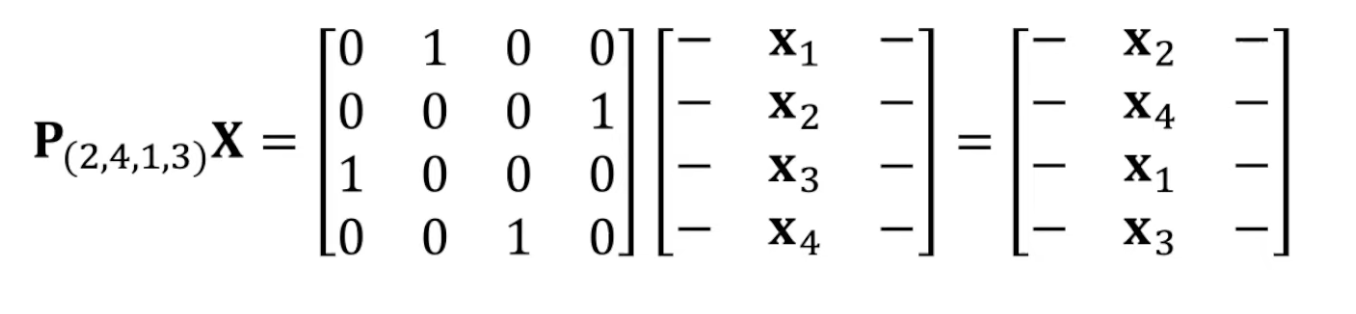
Given this, we can summarise permutation invariance through the following equation:
Permutation invariance of \(f\): For any permutation matrix \(\mathbf{P}\), we require \(f(\mathbf{P}\mathbf{X}) = f(\mathbf{X})\). The output is unaffected by re-ordering the input.
Example: Deep Sets
Given two learnable functions \(\phi,\psi\), the deep sets architecture — proposed initially in 2018 — has the following choice of \(f\):
\[ f(\mathbf{X}) = \phi\left(\sum_{i=1}^{v}\psi(\mathbf{x}_i)\right), \]
where summing the learned functions for each node enforces the permutation invariance property (it doesn’t matter what order you sum — you always get the same result). A concrete example of this would be to choose both \(\phi\) and \(\psi\) to be feed-forward neural networks (also called MLPs/multi-layer perceptrons).
Note that summing here is just one choice of information aggregation — we could have just as easily chosen the maximum, empirical mean etc. The point is that all of these operations are invariant to the order of the input. The optimal way to aggregate information is a design choice, and may vary depending on the problem you’re solving and the properties you want to learn.
In future, we’ll use \(\bigoplus\) to denote a general aggregator function, which needs to be chosen when actually implementing the architecture involving it.
Node-level reasoning and equivariance
You’ll notice that if we choose to aggregate over nodes, we’re actually losing information about each node individually in our output — we can only make a statement about the set as a whole. In some applications, this may not be desirable behaviour; one could imagine wanting to make a classification statement about each node in your graph, or trying to predict a certain quantity on a per-node basis. How do we reconcile this with the notion of not caring about how the input is ordered?
We can zoom out a bit and recognise why we cared about permutation invariance at all: it was to ensure that the set was not accidentally treated as an ordered sequence, which may then propagate an ordering bias into the result of our calculations. However, perhaps there’s a notion of this that we’re happy with when predicting per-node quantities, since we’re more interested in the individual nodes than we are the whole set. If we are able to link each output to each node, then that should be enough to satisfy us, provided that this holds no matter how we shuffle the input.
To formalise this: For any permutation matrix \(\mathbf{P}\), we want to be able to apply \(\mathbf{P}\) to the input, and still be able to link each output to the right node, i.e. \(f(\mathbf{X})\) should also change in the same way. For a general operation, this property is called equivariance: the output changes in the same way as the input if we apply an operation to just the input. Equivalently, we could say that if we applied the operation to the output, the result will be as if we did so for the input. For the case of permutations, we can write the following:
Permutation equivariance of \(f\): For any permutation matrix \(\mathbf{P}\), we require \(f(\mathbf{P}\mathbf{X}) = \mathbf{P}f(\mathbf{X})\). The output changes in the same way as the input.
Aside: Locality as a constraint
Imagine wanting to predict a label on an image, but wanting to stay robust to translations of that image. We could either force the network to learn this property by adding translation as a data augmentation, or we could build it directly into the architecture somehow, e.g. by pooling operations in CNNs (which are equivariant to spacial translations — the pooled values move in-step with the image).
In practice, it’s highly likely that a pure translation of the image is not the only thing to worry about. As an example, imagine taking a picture of a house from two different angles. Now you suddenly have a slightly different shape, and maybe a bird is on the roof in the second picture! We’d like to be robust, then, to not just shifts, but also to any deformations of the input that come along for the ride (see image from slides below).
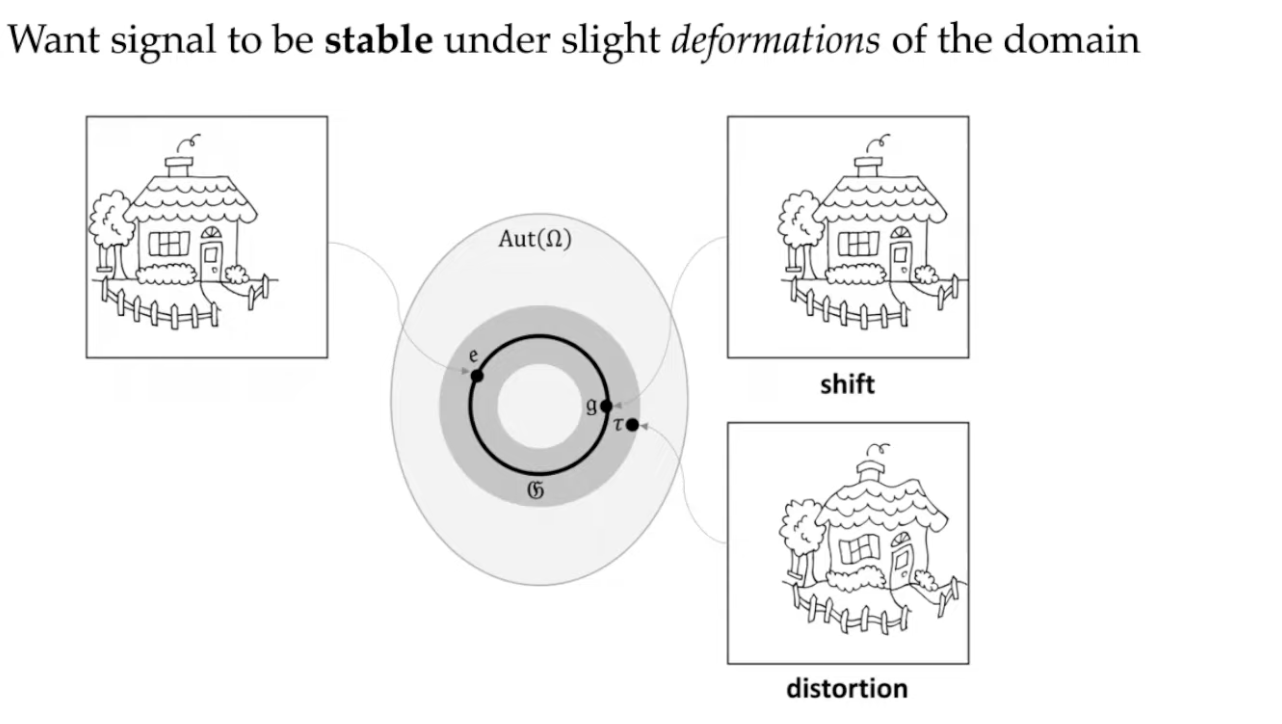
Possible solution: compose many small local operations, but do this very deep (e.g. small kernels in CNNs, but many layers). Local operations should not propagate any errors to the global picture. (?)
How do we enforce locality for equivariant functions on sets?
An easy way to retain equivariance (one node input links to one output) and locality (learning happens on a small set of nodes) is to just operate on each node individually — that is, we apply the same function \(\psi\) to each element separately, and get a set of latents \(\mathbf{h}_i\).
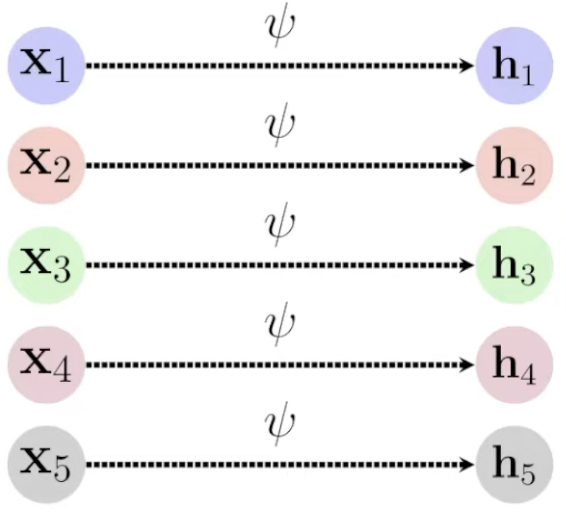
This might sound familiar — it’s the inner part of the Deep Sets architecture (before aggregating with the sum).
Learning on sets: summary
Recall that sets are, by definition, an unordered set of objects, and we’re operating in a way that preserves this behaviour.
Node-level learning: To learn local structure in a set fråom each node while respecting permutation equivariance, we construct a latent vector \(\mathbf{h}_i\) from each \(\mathbf{x}_i\) by applying the same learnable function \(\psi\) to each node, and stack the results:
\[ \mathbf{h}_i = \psi\left(\mathbf{x}_i\right) ; ~~~ \mathbf{H} = \begin{bmatrix} \mathbf{h}_{1} \\ \mathbf{h}_{2} \\ \vdots \\ \mathbf{h}_{n} \end{bmatrix} ~. \]
Set-level learning: We can generalise the above to sets by aggregating the latent vectors, which is permutation invariant with respect to the input nodes. Then (q: how much worse is it if we don’t?), we apply a second learnable function \(\phi\) to arrive at the Deep Sets architecture:
\[ f(\mathbf{X}) = \phi \left(\bigoplus_i \psi \left(\mathbf{x}_i\right)\right) \]
Is Deep Sets the only way for learning on sets?
For many sets, apparently so! There are proofs referenced in the lectures that state that any learnable function that’s permutation invariant on sets can be reduced to the same expressivity as Deep Sets. Example: PointNet.
This is a function \(f\) applied to two different orderings, or permutations of nodes, and we’re requiring that they’re equal in output. To permute the nodes is to change their order; we want this condition of equality to hold over all possible permutations.
We can write permutations of \(\mathbf{X}\) as the product of \(\mathbf{X}\) with some permutation matrix \(\mathbf{P}\), which is square in the feature dimension \(v\), and has exactly one 1 in each row and column. The only result of applying \(\mathbf{P}\) is the reordering of the feature vector order. Example:
Given this, we can summarise permutation invariance through the following equation:
Permutation invariance of \(f\): For any permutation matrix \(\mathbf{P}\), we require \(f(\mathbf{P}\mathbf{X}) = f(\mathbf{X})\). The output is unaffected by re-ordering the input.
Example: Deep Sets
Given two learnable functions \(\phi,\psi\), the deep sets architecture — proposed initially in 2018 — has the following choice of \(f\):
\[ f(\mathbf{X}) = \phi\left(\sum_{i=1}^{v}\psi(\mathbf{x}_i)\right), \]
where summing the learned functions for each node enforces the permutation invariance property (it doesn’t matter what order you sum — you always get the same result). A concrete example of this would be to choose both \(\phi\) and \(\psi\) to be feed-forward neural networks (also called MLPs/multi-layer perceptrons).
Note that summing here is just one choice of information aggregation — we could have just as easily chosen the maximum, empirical mean etc. The point is that all of these operations are invariant to the order of the input. The optimal way to aggregate information is a design choice, and may vary depending on the problem you’re solving and the properties you want to learn.
In future, we’ll use \(\bigoplus\) to denote a general aggregator function, which needs to be chosen when actually implementing the architecture involving it.
Node-level reasoning and equivariance
You’ll notice that if we choose to aggregate over nodes, we’re actually losing information about each node individually in our output — we can only make a statement about the set as a whole. In some applications, this may not be desirable behaviour; one could imagine wanting to make a classification statement about each node in your graph, or trying to predict a certain quantity on a per-node basis. How do we reconcile this with the notion of not caring about how the input is ordered?
We can zoom out a bit and recognise why we cared about permutation invariance at all: it was to ensure that the set was not accidentally treated as an ordered sequence, which may then propagate an ordering bias into the result of our calculations. However, perhaps there’s a notion of this that we’re happy with when predicting per-node quantities, since we’re more interested in the individual nodes than we are the whole set. If we are able to link each output to each node, then that should be enough to satisfy us, provided that this holds no matter how we shuffle the input.
To formalise this: For any permutation matrix \(\mathbf{P}\), we want to be able to apply \(\mathbf{P}\) to the input, and still be able to link each output to the right node, i.e. \(f(\mathbf{X})\) should also change in the same way. For a general operation, this property is called equivariance: the output changes in the same way as the input if we apply an operation to just the input. Equivalently, we could say that if we applied the operation to the output, the result will be as if we did so for the input. For the case of permutations, we can write the following:
Permutation equivariance of \(f\): For any permutation matrix \(\mathbf{P}\), we require \(f(\mathbf{P}\mathbf{X}) = \mathbf{P}f(\mathbf{X})\). The output changes in the same way as the input.
Aside: Locality as a constraint
Imagine wanting to predict a label on an image, but wanting to stay robust to translations of that image. We could either force the network to learn this property by adding translation as a data augmentation, or we could build it directly into the architecture somehow, e.g. by pooling operations in CNNs (which are equivariant to spacial translations — the pooled values move in-step with the image).
In practice, it’s highly likely that a pure translation of the image is not the only thing to worry about. As an example, imagine taking a picture of a house from two different angles. Now you suddenly have a slightly different shape, and maybe a bird is on the roof in the second picture! We’d like to be robust, then, to not just shifts, but also to any deformations of the input that come along for the ride (see image from slides below).
Possible solution: compose many small local operations, but do this very deep (e.g. small kernels in CNNs, but many layers). Local operations should not propagate any errors to the global picture. (?)
How do we enforce locality for equivariant functions on sets?
An easy way to retain equivariance (one node input links to one output) and locality (learning happens on a small set of nodes) is to just operate on each node individually — that is, we apply the same function \(\psi\) to each element separately, and get a set of latents \(\mathbf{h}_i\).
This might sound familiar — it’s the inner part of the Deep Sets architecture (before aggregating with the sum).
Learning on sets: summary
Recall that sets are, by definition, an unordered set of objects, and we’re operating in a way that preserves this behaviour.
Node-level learning: To learn local structure in a set fråom each node while respecting permutation equivariance, we construct a latent vector \(\mathbf{h}_i\) from each \(\mathbf{x}_i\) by applying the same learnable function \(\psi\) to each node, and stack the results:
\[ \mathbf{h}_i = \psi\left(\mathbf{x}_i\right) ; ~~~ \mathbf{H} = \begin{bmatrix} \mathbf{h}_{1} \\ \mathbf{h}_{2} \\ \vdots \\ \mathbf{h}_{n} \end{bmatrix} ~. \]
Set-level learning: We can generalise the above to sets by aggregating the latent vectors, which is permutation invariant with respect to the input nodes. Then (q: how much worse is it if we don’t?), we apply a second learnable function \(\phi\) to arrive at the Deep Sets architecture:
\[ f(\mathbf{X}) = \phi \left(\bigoplus_i \psi \left(\mathbf{x}_i\right)\right) \]
Is Deep Sets the only way for learning on sets?
For many sets, apparently so! There are proofs referenced in the lectures that state that any learnable function that’s permutation invariant on sets can be reduced to the same expressivity as Deep Sets. Example: PointNet.