Introduction¶
XPandas (extended Pandas.) implements 1D and 2D data containers for storing type-heterogeneous tabular data of any type, and encapsulates feature extraction and transformation modelling in an sklearn-compatible transformer interface.
Description¶
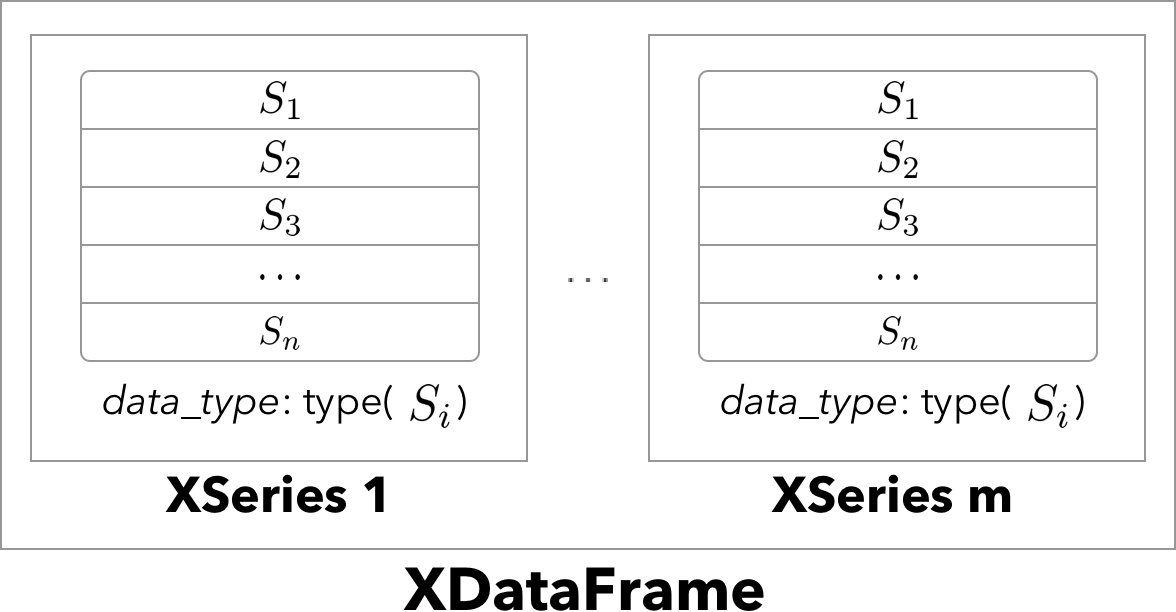
XPandas provides universal 1D typed list (XSeries) and 2D type-heterogeneous data-frame (XDataFrame) containers and provides an extended sklearn-like transformer classes interfacing said containers. Transformers can be used for automated feature extraction and map-reduce style transformations but are not limited to it.
XSeries is based on pandas.Series that can store objects of any type. Example would be a series of image containers, or a series of pandas.Series objects stored as XSeries. XSeries can be visualised according to a schema.

XDataFrame extends pandas.DataFrame by allowing arbitrary object types per column. It provides the same convenient sub-setting interface and extended abstract access methods. Each column is internally stored as an XSeries container, all of same length.
One example could be a medical data set where each row is a different patient, say, in a hospital. The columns would correspond to a type-heterogeneous set of features like numbers (age, height, weight, etc.), categorical (gender, hair color, etc.), images (x-ray pictures), time series (heat beat, lab history), and other parts of a medical record.
With XDataFrame one can store all this information in a single 2D data container instead of a tedious collection of custom nested lists or arrays.
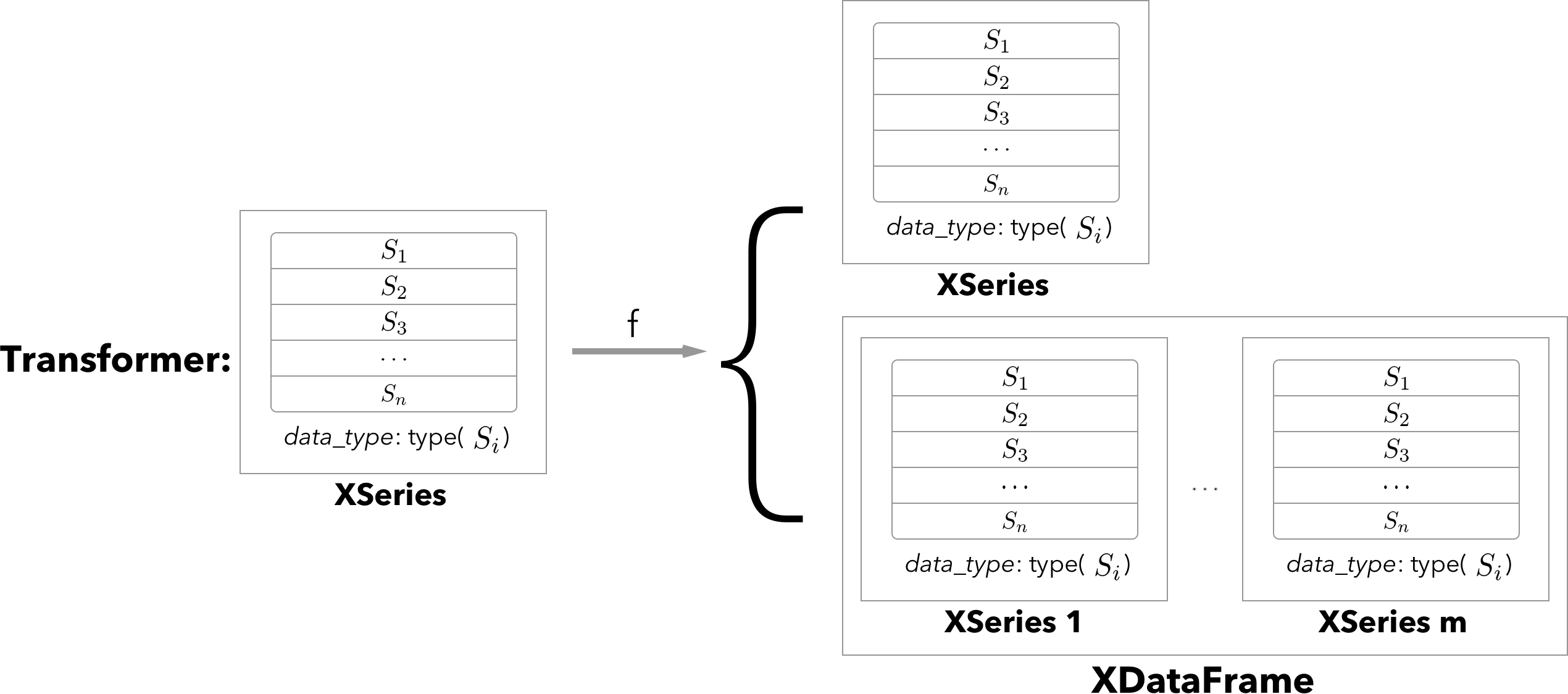
Another advantage of XPandas is the clean interface it provides to ready-to-go machine learning algorithms in scikit-learn. The transformers interface can be used to easily convert the types in a XDataFrame to the primitive types with which sklearn can interface, as part of a modelling pipeline. In the example with patients data, one may want to extract summary features from each pandas.Series, or extract features from each image, say in a deep learning model.
More technically, the implemented XSeriesTransformer class allows for the implementation of transformation defaults for XSeries; similarly XDataFrameTransformer implements a transformation for XDataFrame type objects. From a mathematical point of view XSeriesTransformer encapsulate abstract functions of the type XSeries -> XSeries or XDataFrame whereas XDataFrameTransformer represents mappings from XDataFrame -> XDataFrame. Each of the transformers follow the familiar fit/transform/parameters API of sklearn.
Data types¶
Notably, XPandas comes with several pre-implemented transformers for the most common non-primitive data types.
Time series
TimeSeriesTransformer(features)— extractfeaturesfrom each series.featuresis a subset of [ ‘mean’, ‘std’, ‘max’, ‘min’, ‘median’, ‘quantile_25’, ‘quantile_75’, ‘quantile_90’, ‘quantile_95’]TimeSeriesWindowTransformer(windows_size)— calculate rolling mean with givenwindows_sizeTsFreshSeriesTransformer— extract features using tsfresh package
Image
ImageTransformer— Performs image transformation based on skimage transformation function
Categorical data
BagOfWordsTransformer(dictionary)— Performs bag-of-features transformer for strings of any categorical data
XPandas also allows for pipelining, via the PipeLineChain
transformer, which can chain multiple transformers and scikit-learn
predictor into a single pipeline. PipeLineChain is based on the
scikit-learn
Pipeline.
