15 Code walkthrough
SPC is implemented in Rust, and its code can be found here. This is an unusual implementation choice in the data science world, so this page has some notes about it.
15.1 Generally useful techniques
The code-base makes use of some techniques that may be generally applicable to other projects, independent of the language chosen.
15.1.1 Split code into two stages
Agent-based models and spatial interaction models require some kind of input. Often the effort to transform external data into this input can exceed that of the simulation component. Cleanly separating the two problems has some advantages:
- iterate on the simulation faster, without processing raw data every run
- reuse the prepared input for future projects
- force thinking about the data model needed by the simulation, and transform the external data into that form
SPC is exactly this first stage, originally split from ASPICS when further uses of the same population data were identified.
15.1.2 Explicit data schema
Dynamically typed languages like Python don’t force you to explicitly list the shape of input data. It’s common to read CSV files with pandas, filter and transform the data, and use that throughout the program. This can be quick to start prototyping, but is hard to maintain longer-term. Investing in the process of writing down types:
- makes it easier for somebody new to understand your system – they can first focus on what you’re modeling, instead of how that’s built up from raw data sources
- clarifies what data actually matters to your system; you don’t carry forward unnecessary input
- makes it impossible to express invalid states
- One example is here – per person and activity, there’s a list of venues the person may visit, along with a probability of going there. If the list of venues and list of probabilities are stored as separate lists or columns, then their length may not match.
- reuse the prepared input for future projects
There’s a variety of techniques for expressing strongly typed data:
15.1.3 Type-safe IDs
Say your data model has many different objects, each with their own ID – people, households, venues, etc. You might store these in a list and use the index as an ID. This is fine, but nothing stops you from confusing IDs and accidentally passing in venue 5 to a function instead of household 5. In Rust, it’s easy to create “wrapper types” like this and let the compiler prevent these mistakes.
This technique is also useful when preparing external data. GTFS data describing public transit routes and timetables contains many string IDs – shapes, trips, stops, routes. As soon as you read the raw input, you can store the strings in more precise types that prevent mixing up a stop ID and route ID.
15.1.4 Idempotent data preparation
If you’re iterating on your initialisation pipeline’s code, you probably don’t want to download a 2GB external file every single run. A common approach is to first test if a file exists and don’t download it again if so. In practice, you may also need to handle unzipping files, showing a progress bar while downloading, and printing clear error messages. This codebase has some common code for doing this in Rust. We intend to publish a separate library to more easily call in your own code.
15.1.5 Logging with structure
It’s typical to print information as a complex pipeline runs, for the user to track progress and debug problems. But without any sort of organization, it’s hard to follow what steps take a long time or encounter problems. What if your logs could show the logical structure of your pipeline and help you understand where time is spent?
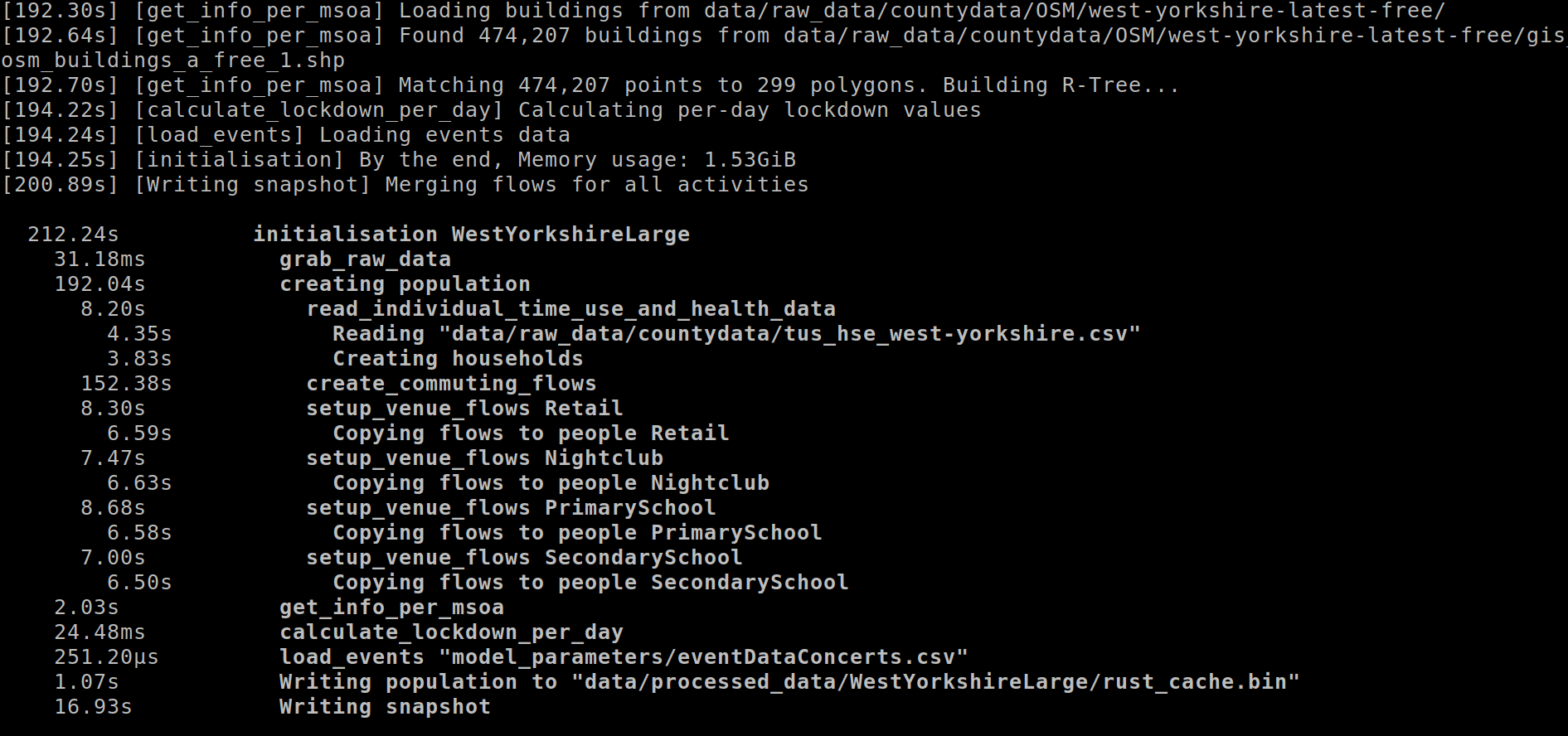
The screenshot above shows a summary printed at the end of a long pipeline run. It’s immediately obvious that the slowest step is creating commuting flows.
This codebase uses the tracing framework for logging, with a custom piece to draw the tree. (We’ll publish this as a separate library once it’s more polished.) The tracing framework is hard to understand, but the main conceptual leap over regular logging framworks is the concept of a span. When your code starts one logical step, you call a method to create a new span, and when it finishes, you close that span. Spans can be nested in any way – create_commuting_flows happens within the larger step of creating population.
15.1.6 Determinism
Given the same inputs, your code should always produce identical output, no matter where it’s run or how many times. Otherwise, debugging problems becomes very tedious, and it’s more difficult to make conclusions from results. Of course, many projects have a stochastic element – but this should be controlled by a random number generator (RNG) seed, which is part of the input. You vary the seed and repeat the program, then reason about the distribution of results.
Aside from organizing your code to let a single RNG seed influence everything, another possible source of non-determinism is iteration order. In Rust, a HashMap could have different order every time it’s used, so we use a BTreeMap instead when this matters. In Python, dictionaries are ordered. Be sure to check for your language.
15.2 Protocol buffers
SPC uses protocol buffers v2 for output. This has some advantages explained the “explicit data schema” section above.
Note that we chose proto2 instead of proto3, because proto3 doesn’t support required fields. This is done to allow schemas to evolve better over time, but this isn’t a feature SPC makes use of. There’s no need to have new code work with old data, or vice versa – if the schema is updated, downstream code should adapt accordingly and use the updated input files.
Note also that protocol buffers don’t easily support type-safe wrappers around numeric IDs, so downstream code has to be careful not to mix up household, venue, and person IDs. For this reason, SPC internally doesn’t use the auto-generated protobuf code until the very end of the pipeline. It’s always possible to be more precise with native Rust types, and convert to the less strict types later.
15.3 An example of the power of static type checking
Imagine we want to add a new activity type to represent people going to university and higher education. SPC already has activities for primary and secondary school, so we’ll probably want to follow those as a guide. In any language, we could search the codebase for relevant terms to get a sense of what to update. In languages like Python without an up-front compilation step, if we fail to update something or write blatantly incorrect code (such as making a typo in variable names or passing a list where a string was expected), we only find out when that code happens to run. In pipelines with many steps and large input files, it could be a while before we reach the problematic code.
Let’s walk through the same exercise for SPC’s Rust code. We start by adding a new University case to the Activity enum. If we try to compile the code here (with cargo check or an IDE), we immediately get 4 errors.
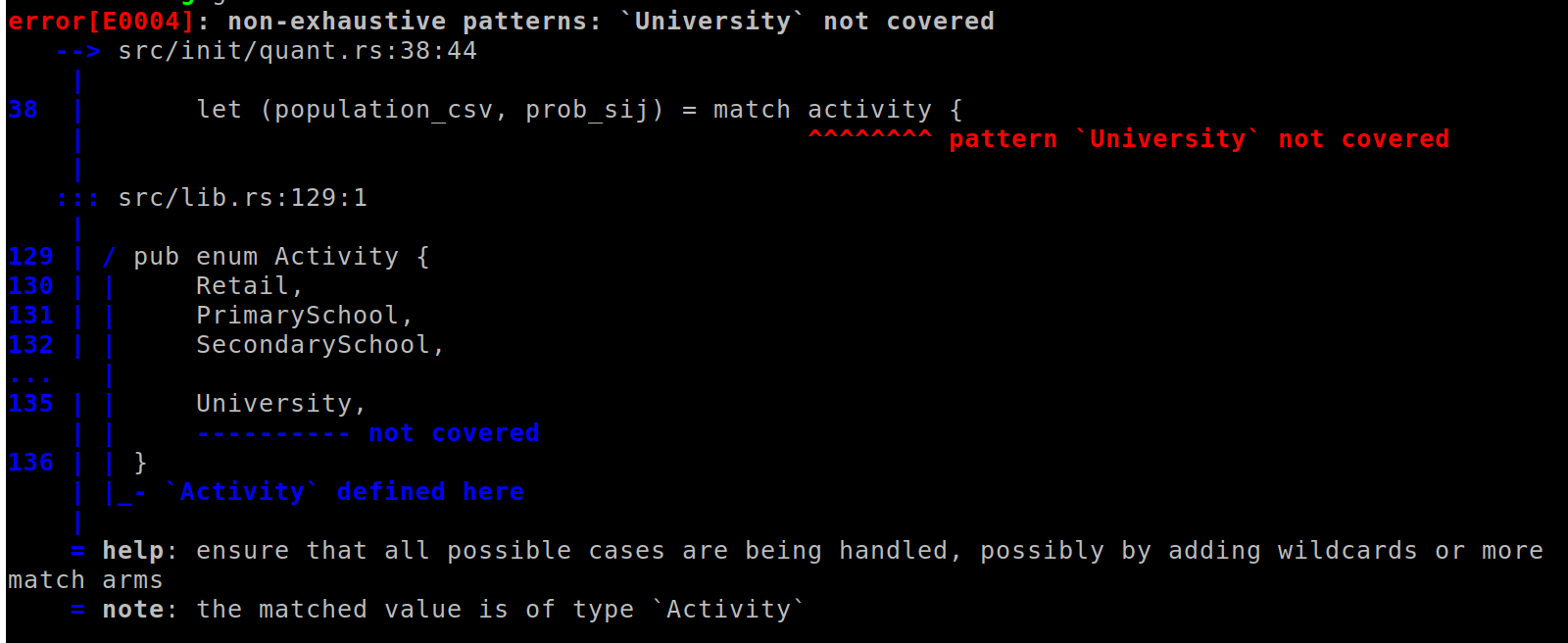
Three of the errors are in the QUANT module. The first is here. It’s immediately clear that for retail and primary/secondary school, we read in two files from QUANT representing venues where these activities take place and the probability of going to each venue. Even if we were unfamiliar with this codebase, the compiler has told us one thing we’ll need to figure out, and where to wire it up.
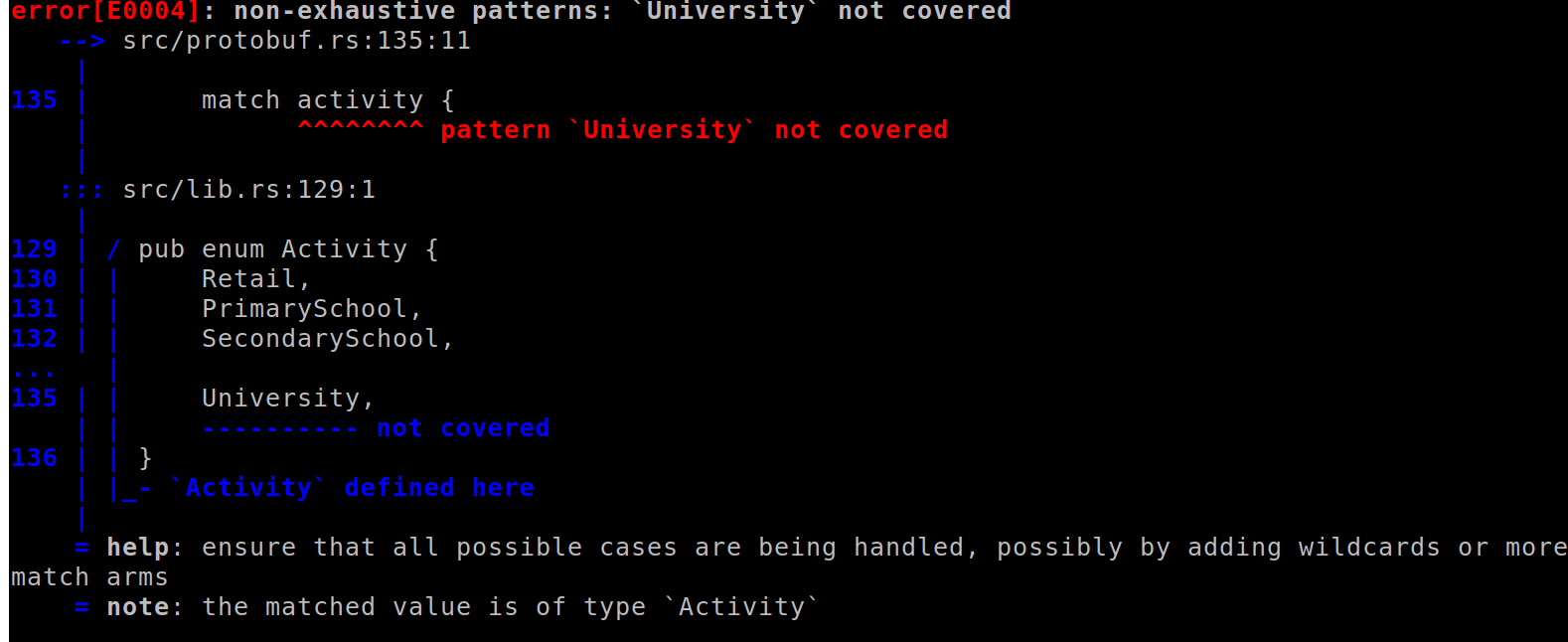
The other error is in the code that writes the protobuf output. Similarly, we need a way to represent university activities in the protobuf scheme.
Extending an unfamiliar code-base backed by compiler errors is a very guided experience. If you wanted to add more demographic attributes to people or energy use information to households, you don’t need to guess all of the places in the code you’ll need to update. You can just add the field, then let the compiler tell you all places where those objects get created.