Quickstart#
AutoEmulate’s goal is to make it easy to create an emulator for your simulation. Here’s the basic workflow:
import numpy as np
import random
import torch
from autoemulate.compare import AutoEmulate
from autoemulate.experimental_design import LatinHypercube
from autoemulate.simulations.projectile import simulate_projectile
seed = 43
np.random.seed(seed)
random.seed(seed)
_ = torch.manual_seed(seed)
Design of Experiments#
Before we build an emulator or surrogate model, we need to get a set of input/output pairs from the simulation. This is called the Design of Experiments (DoE) and is currently not a key part of AutoEmulate, as this step is tricky to automate and will run on more complex compute infrastructure for expensive simulations. There are lots of sampling techniques, but here we are using Latin Hypercube Sampling.
Below, simulate_projectile is a simulation for a projectil motion with drag (see here for details). It takes two inputs, the drag coefficient (on a log scale) and the velocity and outputs the distance the projectile travelled. We sample 100 sets of inputs X using a Latin Hypercube Sampler and run the simulator for those inputs to get the outputs y.
# sample from a simulation
lhd = LatinHypercube([(-5., 1.), (0., 1000.)]) # (upper, lower) bounds for each parameter
X = lhd.sample(100)
y = np.array([simulate_projectile(x) for x in X])
X.shape, y.shape
((100, 2), (100,))
Comparing emulators#
This is the core of AutoEmulate. With a set of inputs / outputs, we can run a full machine learning pipeline, including data processing, model fitting, model selection and potentially hyperparameter optimisation in just a few lines of code. First, we initialise an AutoEmulate object. Then, we run setup(X, y), providing the simulation inputs and outputs. Lastly, compare() will fit a range of different models to the data and evaluate them using cross-validation, returning the best emulator.
# compare emulator models
ae = AutoEmulate()
ae.setup(X, y)
ae.compare()
AutoEmulate is set up with the following settings:
| Values | |
|---|---|
| Simulation input shape (X) | (100, 2) |
| Simulation output shape (y) | (100,) |
| Proportion of data for testing (test_set_size) | 0.2 |
| Scale input data (scale) | True |
| Scaler (scaler) | StandardScaler |
| Scale output data (scale_output) | True |
| Scaler output (scaler_output) | StandardScaler |
| Do hyperparameter search (param_search) | False |
| Reduce input dimensionality (reduce_dim) | False |
| Reduce output dimensionality (reduce_dim_output) | False |
| Cross validator (cross_validator) | KFold |
| Parallel jobs (n_jobs) | 1 |
InputOutputPipeline(regressor=Pipeline(steps=[('scaler', StandardScaler()),
('model', GaussianProcess())]),
transformer=Pipeline(steps=[('scaler_output',
StandardScaler())]))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
InputOutputPipeline(regressor=Pipeline(steps=[('scaler', StandardScaler()),
('model', GaussianProcess())]),
transformer=Pipeline(steps=[('scaler_output',
StandardScaler())]))Pipeline(steps=[('scaler', StandardScaler()), ('model', GaussianProcess())])StandardScaler()
GaussianProcess()
Pipeline(steps=[('scaler_output', StandardScaler())])StandardScaler()
We can have a look at the average cross-validation results for each model:
ae.summarise_cv()
| preprocessing | model | short | fold | rmse | r2 | |
|---|---|---|---|---|---|---|
| 0 | None | GaussianProcess | gp | 1 | 74.243673 | 0.999720 |
| 1 | None | GaussianProcess | gp | 2 | 157.576591 | 0.999355 |
| 2 | None | RadialBasisFunctions | rbf | 1 | 139.068193 | 0.999018 |
| 3 | None | GaussianProcess | gp | 4 | 317.109698 | 0.997962 |
| 4 | None | RadialBasisFunctions | rbf | 4 | 388.646574 | 0.996939 |
| 5 | None | RadialBasisFunctions | rbf | 0 | 298.396470 | 0.996302 |
| 6 | None | GaussianProcess | gp | 3 | 1431.532523 | 0.987998 |
| 7 | None | GaussianProcess | gp | 0 | 558.756442 | 0.987033 |
| 8 | None | RadialBasisFunctions | rbf | 2 | 733.662538 | 0.986011 |
| 9 | None | RandomForest | rf | 1 | 771.364588 | 0.969775 |
| 10 | None | GradientBoosting | gb | 1 | 863.049885 | 0.962163 |
| 11 | None | SupportVectorMachines | svm | 1 | 997.355912 | 0.949470 |
| 12 | None | SupportVectorMachines | svm | 0 | 1189.771143 | 0.941209 |
| 13 | None | GradientBoosting | gb | 4 | 1886.826661 | 0.927854 |
| 14 | None | GradientBoosting | gb | 2 | 1739.684588 | 0.921342 |
| 15 | None | RadialBasisFunctions | rbf | 3 | 3968.935469 | 0.907746 |
| 16 | None | SupportVectorMachines | svm | 2 | 2037.033993 | 0.892155 |
| 17 | None | RandomForest | rf | 2 | 2210.868459 | 0.872964 |
| 18 | None | SupportVectorMachines | svm | 4 | 2753.743687 | 0.846329 |
| 19 | None | LightGBM | lgbm | 1 | 1777.973496 | 0.839418 |
| 20 | None | RandomForest | rf | 4 | 2891.772745 | 0.830537 |
| 21 | None | SecondOrderPolynomial | sop | 4 | 2984.203131 | 0.819531 |
| 22 | None | SecondOrderPolynomial | sop | 2 | 2931.778339 | 0.776610 |
| 23 | None | GradientBoosting | gb | 3 | 6630.237257 | 0.742548 |
| 24 | None | LightGBM | lgbm | 2 | 3237.803474 | 0.727540 |
| 25 | None | SecondOrderPolynomial | sop | 3 | 7341.981017 | 0.684307 |
| 26 | None | RandomForest | rf | 3 | 7537.009532 | 0.667312 |
| 27 | None | SecondOrderPolynomial | sop | 0 | 2857.074175 | 0.660979 |
| 28 | None | SecondOrderPolynomial | sop | 1 | 2758.736100 | 0.613396 |
| 29 | None | SupportVectorMachines | svm | 3 | 8997.017520 | 0.525938 |
| 30 | None | LightGBM | lgbm | 4 | 5183.813487 | 0.455442 |
| 31 | None | LightGBM | lgbm | 3 | 10635.304707 | 0.337573 |
| 32 | None | RandomForest | rf | 0 | 4413.762209 | 0.190902 |
| 33 | None | LightGBM | lgbm | 0 | 4549.348847 | 0.140429 |
| 34 | None | GradientBoosting | gb | 0 | 5064.364357 | -0.065205 |
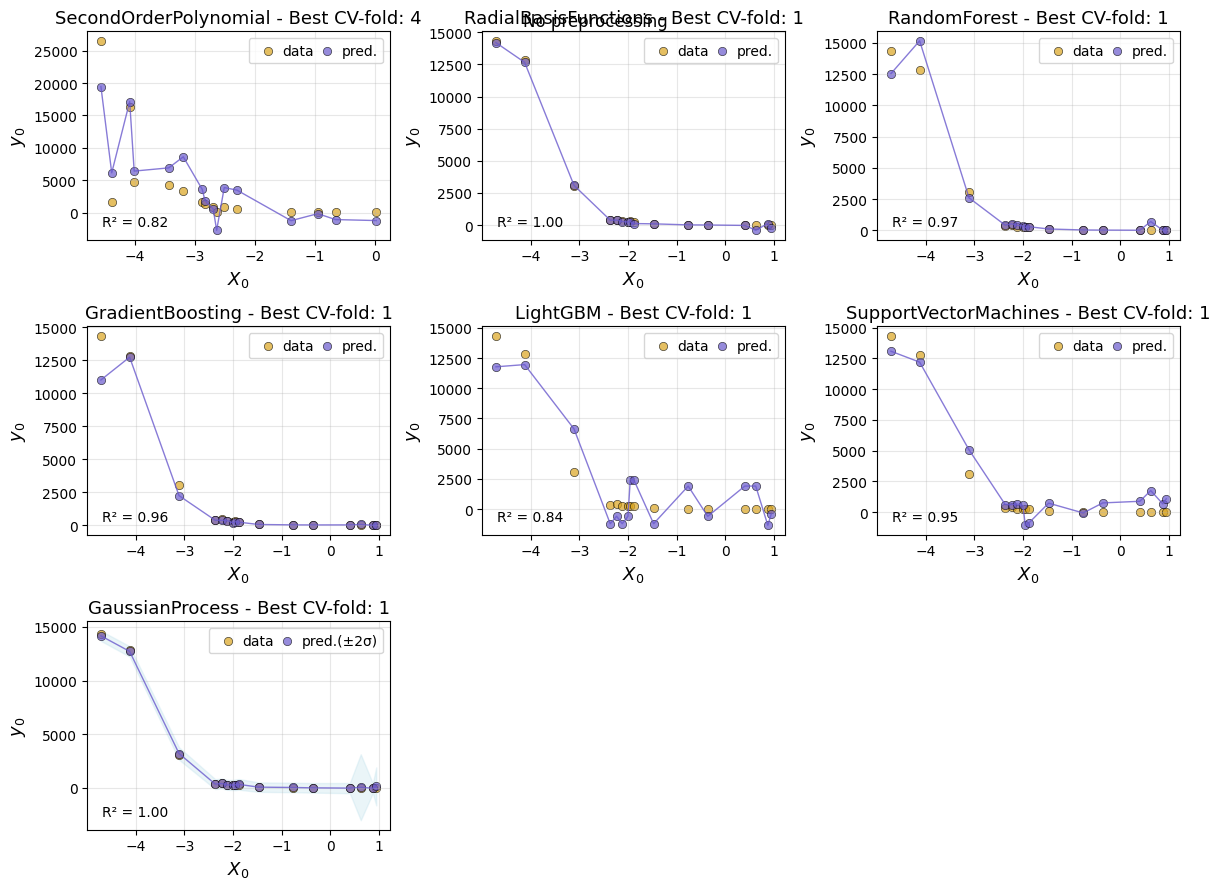
And create plots comparing the models:
ae.plot_cv()
Using best preprocessing method: None
No preprocessing was applied (using raw target values)
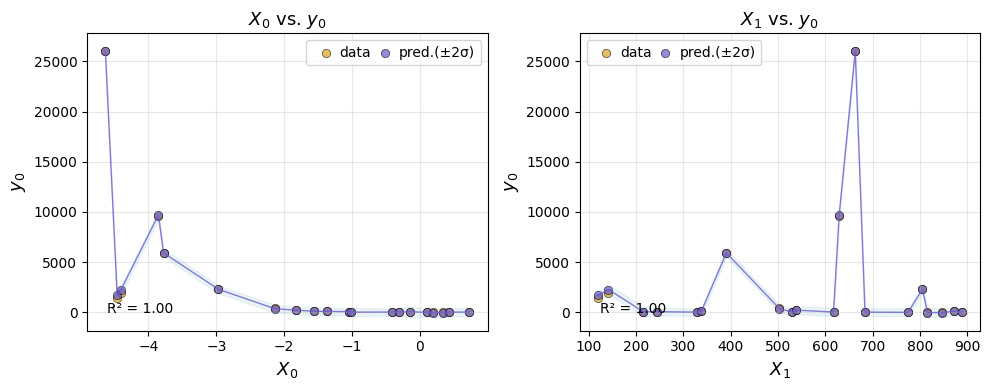
Evaluating on the test set#
AutoEmulate has already split the data into a training set and a test set. After looking at the cross-validation results, we can retrieve a fitted emulator and evaluate it on the test set. The GP predicts well on unseen data.
gp = ae.get_model("GaussianProcess")
ae.evaluate(gp)
| model | short | preprocessing | rmse | r2 | |
|---|---|---|---|---|---|
| 0 | GaussianProcess | gp | None | 100.5854 | 0.9997 |
But it’s always useful to plot the predictions too.
ae.plot_eval(gp, input_index=[0, 1])
Refitting the emulator#
Before applying the emulator, we refit it on the entire dataset, including training and test set. This is done with the refit() method.
gp_final = ae.refit(gp)
Predictions#
We can use the best model to make predictions for new inputs. Emulators in AutoEmulate are scikit-learn estimators, so we can use the predict method to make predictions.
gp_final.predict(X[:10])
array([ 5.92758299e+03, 8.09264413e+03, 1.64323793e+04, 8.03628410e+03,
1.02650134e+02, -4.12283436e+00, 5.90682078e+00, 5.95790294e+01,
1.08375388e+04, 7.03506540e+00])