Scaling Sensitivity Analysis with Emulation#
In this tutorial we demonstrate how AutoEmulate can facilitate finding the best emulator for the simulation of fluid flow in a cardiovascular system.
By the end of this tutorial:
Participants will learn how to use
Autoemulatefor the emulation of a real-world simulation in an end-to-end pipeline.Participants will learn how to explore the relationship between underlying cardiac health parameters and non-invasive measures using synthetic data, with a focus on how these insights can improve understanding and estimation of key cardiovascular dynamics
The Problem#
In the field of cardiovascular modeling, capturing the dynamics of blood flow and the associated pressures and volumes within the vascular system is crucial for understanding heart function and disease. Physics-based models that accurately represent these dynamics often require significant computational resources, making them challenging to apply in large-scale or real-time scenarios. Emulation techniques provide a way to achieve high-fidelity simulations of the cardiovascular system, allowing for efficient and accurate analysis of key hemodynamic parameters.
Content#
This tutorial includes:
Setting up a simulation : The system simulated is a tube with an input flow rate at any given time. The tube is divided to 10 compartments which allows for the study of the pressure and flow rate at various points in the tube.
Running the simulation for 60 sets of parameters sampled from the parameter space.
Using Autoemulate to find the best emulator fot this simulation
Assessing model accuracy, performing sensitivity analysis.
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm
from autoemulate.compare import AutoEmulate
from sklearn.metrics import r2_score
from autoemulate.experimental_design import LatinHypercube
from autoemulate.simulations.flow_functions import FlowProblem
show_progress = False if os.getenv("JUPYTER_BOOK_BUILD", "false").lower() == "true" else True
Define your simulator#
This simulator simulates a vessel divided to 10 compartments.
Parameters#
The simulation parameters include :
R (Resistance): Represents the resistance to blood flow in blood vessels, akin to the hydraulic resistance caused by vessel diameter and blood viscosity (Analogous to electrical resistor).
L (Inductance): Represents the inertial effects of blood flow, capturing how blood resists changes in its velocity (Analogous to electrical inductor).
C (Capacitance): Represents the compliance or elasticity of blood vessels, primarily large arteries, which store and release blood volume with changes in pressure (Analogous to a capacitor).
Boundary conditions#
Neumann boundary condition : Specifies the derivative of the variable at the boundary.
Dirichlet Boundary condition : Specifies the value of the variable directly at the boundary.
The setup#
The input flow rate in each compartment is \(Q_i(t)\) for the \(i^{th}\) compartment and the output flow rate is \(Q_{i+1}(t)\).
\(Q_0(t) = \begin{cases} A \cdot \sin^2\left(\frac{\pi}{t_d} t\right), & \text{if } 0 \leq t < T, \\ 0, & \text{otherwise}. \end{cases}\)
Where:
\(Q_0(t)\) is the input pulse function (flow rate) at time t
A is the amplitude of the pulse
\(t_d\) is the pulse duration.
fp = FlowProblem(ncycles=10, ncomp=10, amp=900.)
fp.generate_pulse_function()
Solve#
Pressure in Each Compartment (\(P_i\)): This determines how the pressure in each compartment evolves over time, based on the inflow (\(Q_i(t)\)) and the outflow (\(Q_{i+1}(t)\)). where \(i\) is the number of compartment.

\(\frac{dP_i}{dt} = \frac{1}{C_n} \left( Q_i(t) - Q_{i+1}(t) \right)\) where, \(C_n = \frac{C}{n_\text{comp}}\)
Flow rate equation (\(Q_i\)): This governs how the flow in each compartment changes over time, depending on the pressures in the neighboring compartments and the resistance and inertance properties of each compartment.
\(\frac{dQ_i}{dt} = \frac{1}{L_n} \left( P_i - P_{10} - R_n Q_i(t) \right)\), where \(L_n = \frac{L}{n_\text{comp}}, \quad R_n = \frac{R}{n_\text{comp}}\)
fp.solve()
Plotting Pressure and flow rate#
Here the pressure and flow rate have been plotted for all 10 compartments (the colour of the line fades for later compartments). As it is apaprent from the figure the peak pressure as well as the flow rate drops for the later compartments.
fig, ax = fp.plot_res()
plt.show()

Experimental Design#
We set up the parameters for the simulation and their range. The range is set to the domain of interest for the problem we are solving. Furthermore, it is important to restrict the range to enhance the fitting of the model.
## specify valid parameter ranges
# Dictionary with parameters and their scaled ranges for the blood flow model
parameters_range = {
'T': tuple(np.array([0.5, 1.5]) * 1.0), # Cardiac cycle period (s)
'td': tuple(np.array([0.8, 1.2]) * 0.2), # Pulse duration (s)
'amp': tuple(np.array([0.8, 1.2]) * 900.0), # Amplitude (e.g., pressure or flow rate)
'dt': tuple(np.array([0.5, 1.5]) * 0.001), # Time step (s)
'C': tuple(np.array([0.8, 1.2]) * 38.0), # Compliance (unit varies based on context)
'R': tuple(np.array([0.8, 1.2]) * 0.06), # Resistance (unit varies based on context)
'L': tuple(np.array([0.8, 1.2]) * 0.0017), # Inductance (unit varies based on context)
'R_o': tuple(np.array([0.8, 1.2]) * 0.025), # Outflow resistance (unit varies based on context)
'p_o': tuple(np.array([0.9, 1.1]) * 10.0) # Initial pressure (unit varies based on context)
}
# Output the dictionary for verification
parameters_range
{'T': (0.5, 1.5),
'td': (0.16000000000000003, 0.24),
'amp': (720.0, 1080.0),
'dt': (0.0005, 0.0015),
'C': (30.400000000000002, 45.6),
'R': (0.048, 0.072),
'L': (0.00136, 0.0020399999999999997),
'R_o': (0.020000000000000004, 0.03),
'p_o': (9.0, 11.0)}
Sampling parameters#
Secondly we sample the parameter space usning the Latin hypercube sampling (LHS) method.
Latin Hypercube Sampling (LHS) is a statistical method used for generating a sample of plausible values from a multidimensional distribution and guarantees that every sample is drawn from a different quantile of the underlying distribution. It is particularly effective for uncertainty quantification, sensitivity analysis, and simulation studies where the goal is to explore the behavior of a system or a model across a wide range of input parameter values.
## sample from parameter range
N_samples = 60
lhd = LatinHypercube(parameters_range.values())
sample_array = lhd.sample(N_samples)
sample_df = pd.DataFrame(sample_array, columns=parameters_range.keys())
print("Number of parameters", sample_df.shape[1], "Number of samples from each parameter", sample_df.shape[0])
sample_df.head()
Number of parameters 9 Number of samples from each parameter 60
| T | td | amp | dt | C | R | L | R_o | p_o | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.732224 | 0.183449 | 805.937651 | 0.000549 | 30.480662 | 0.048385 | 0.001676 | 0.027007 | 10.683468 |
| 1 | 1.279778 | 0.174137 | 840.489773 | 0.001014 | 39.053697 | 0.057204 | 0.001759 | 0.020744 | 10.929880 |
| 2 | 0.635450 | 0.214702 | 778.987416 | 0.000844 | 33.970416 | 0.066353 | 0.001981 | 0.024624 | 9.760243 |
| 3 | 1.133886 | 0.175115 | 982.217493 | 0.001412 | 32.254234 | 0.067946 | 0.001742 | 0.022197 | 10.475776 |
| 4 | 0.753490 | 0.217859 | 855.814718 | 0.001077 | 36.883378 | 0.065816 | 0.001853 | 0.022710 | 9.439313 |
Simulate#
Here we run the simulation which involves:
1- Generating the pulse functions.
2- Solving the differential equations.
3- Returning the pressure and flow rate in y for every set of parameters sampled (every row of sample_df data frame).
The full output of the simulation is quite large for fitting an emulator model. Therefore, it is standard practice to grab the most relavant information for training the emulator. Here we have chosen to train the emulator on the maximum pressure in each compartment. There are a variety of outputs that could be considered (max / min / average /mean / median / gradiant / PCA ).
# Fixed parameters: Number of compartments and cycles
ncomp = 10
ncycles = 10
# Function to run a simulation for a given set of parameters
def simulate(param_dict):
fp = FlowProblem(ncycles=ncycles, ncomp=ncomp, **param_dict)
fp.generate_pulse_function()
fp.solve()
return fp, fp.res.t, fp.res.y
Y = []
# Iterate over each sample of parameters
for index, row in tqdm(sample_df.iterrows(), total=len(sample_df), disable=show_progress):
param_dict = row.to_dict()
fp, t, y = simulate(param_dict)
# extract peak pressure
peak_pressure = y[:ncomp, :].max()
Y.append(peak_pressure)
Emulate & Validate#
Here we setup Autoemulate.
The models currently available for performing cross-validation are as follows:
sop: SecondOrderPolynomial
rbf: RadialBasisFunctions
rf: RandomForest
gb: GradientBoosting
lgbm: LightGBM
svm: SupportVectorMachines
gp: GaussianProcess
gpmt: GaussianProcessMT
gps: GaussianProcessSklearn
nns: NeuralNetSk
We have selected four of these models for cross-validation, feel free to explore more!
em = AutoEmulate()
parameter_names = list(parameters_range.keys())
em.setup(sample_df[parameter_names], Y, models = ['gp', 'svm','lgbm'])
best_model = em.compare()
AutoEmulate is set up with the following settings:
| Values | |
|---|---|
| Simulation input shape (X) | (60, 9) |
| Simulation output shape (y) | (60,) |
| Proportion of data for testing (test_set_size) | 0.2 |
| Scale input data (scale) | True |
| Scaler (scaler) | StandardScaler |
| Scale output data (scale_output) | True |
| Scaler output (scaler_output) | StandardScaler |
| Do hyperparameter search (param_search) | False |
| Reduce input dimensionality (reduce_dim) | False |
| Reduce output dimensionality (reduce_dim_output) | False |
| Cross validator (cross_validator) | KFold |
| Parallel jobs (n_jobs) | 1 |
em.summarise_cv()
| preprocessing | model | short | fold | rmse | r2 | |
|---|---|---|---|---|---|---|
| 0 | None | GaussianProcess | gp | 4 | 4.601296 | 0.997381 |
| 1 | None | GaussianProcess | gp | 2 | 8.211435 | 0.986457 |
| 2 | None | GaussianProcess | gp | 1 | 7.025963 | 0.986369 |
| 3 | None | GaussianProcess | gp | 0 | 13.472507 | 0.979226 |
| 4 | None | GaussianProcess | gp | 3 | 14.029158 | 0.971671 |
| 5 | None | SupportVectorMachines | svm | 4 | 41.110365 | 0.790951 |
| 6 | None | SupportVectorMachines | svm | 1 | 27.520986 | 0.790863 |
| 7 | None | SupportVectorMachines | svm | 0 | 52.296934 | 0.686976 |
| 8 | None | SupportVectorMachines | svm | 3 | 65.458740 | 0.383249 |
| 9 | None | SupportVectorMachines | svm | 2 | 55.993055 | 0.370286 |
| 10 | None | LightGBM | lgbm | 4 | 90.127573 | -0.004755 |
| 11 | None | LightGBM | lgbm | 0 | 93.890773 | -0.008954 |
| 12 | None | LightGBM | lgbm | 1 | 66.147771 | -0.208183 |
| 13 | None | LightGBM | lgbm | 2 | 82.674960 | -0.372850 |
| 14 | None | LightGBM | lgbm | 3 | 103.049956 | -0.528517 |
gp = em.get_model("GaussianProcess")
em.evaluate(gp)
| model | short | preprocessing | rmse | r2 | |
|---|---|---|---|---|---|
| 0 | GaussianProcess | gp | None | 10.8928 | 0.982 |
em.plot_eval(gp)
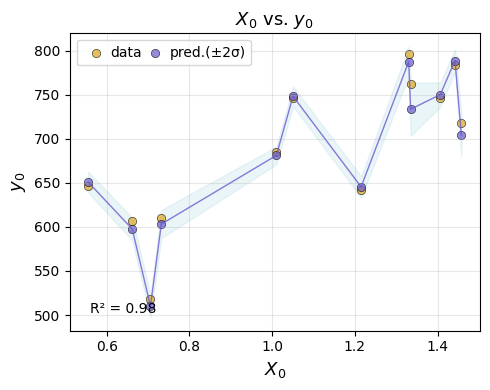
best_emulator = em.refit(gp)
Sensitivity Analysis#
Define the problem by creating a dictionary which contains the names and the boundaries of the parameters
contribution of each parameter , importance of each parameter
S₁: First-order sensitivity index.
S₂: Second-order sensitivity index.
Sₜ: Total sensitivity index.
# Extract parameter names and bounds from the dictionary
parameter_names = list(parameters_range.keys())
parameter_bounds = list(parameters_range.values())
# Define the problem dictionary for Sobol sensitivity analysis
problem = {
'num_vars': len(parameter_names),
'names': parameter_names,
'bounds': parameter_bounds
}
em.sensitivity_analysis(problem=problem)
| output | parameter | index | value | confidence | |
|---|---|---|---|---|---|
| 0 | y1 | T | S1 | 0.003390 | 0.000358 |
| 1 | y1 | td | S1 | 0.024790 | 0.002324 |
| 2 | y1 | amp | S1 | 0.865803 | 0.057668 |
| 3 | y1 | dt | S1 | 0.000559 | 0.000068 |
| 4 | y1 | C | S1 | 0.044220 | 0.004226 |
| 5 | y1 | R | S1 | 0.053151 | 0.004931 |
| 6 | y1 | L | S1 | 0.003082 | 0.000327 |
| 7 | y1 | R_o | S1 | 0.000577 | 0.000069 |
| 8 | y1 | p_o | S1 | 0.000138 | 0.000018 |
| 0 | y1 | T | ST | 0.002597 | 0.005259 |
| 1 | y1 | td | ST | 0.023956 | 0.012740 |
| 2 | y1 | amp | ST | 0.870092 | 0.067742 |
| 3 | y1 | dt | ST | 0.000289 | 0.002042 |
| 4 | y1 | C | ST | 0.046634 | 0.019013 |
| 5 | y1 | R | ST | 0.052692 | 0.019184 |
| 6 | y1 | L | ST | 0.001979 | 0.004900 |
| 7 | y1 | R_o | ST | -0.000323 | 0.001768 |
| 8 | y1 | p_o | ST | 0.001276 | 0.000953 |
| 0 | y1 | (T, td) | S2 | 0.000496 | 0.007510 |
| 1 | y1 | (T, amp) | S2 | 0.000301 | 0.009561 |
| 2 | y1 | (T, dt) | S2 | 0.000250 | 0.007474 |
| 3 | y1 | (T, C) | S2 | 0.000194 | 0.007762 |
| 4 | y1 | (T, R) | S2 | 0.000279 | 0.007845 |
| 5 | y1 | (T, L) | S2 | 0.000159 | 0.007530 |
| 6 | y1 | (T, R_o) | S2 | 0.000297 | 0.007527 |
| 7 | y1 | (T, p_o) | S2 | 0.000253 | 0.007516 |
| 8 | y1 | (td, amp) | S2 | 0.000138 | 0.024502 |
| 9 | y1 | (td, dt) | S2 | -0.000073 | 0.020543 |
| 10 | y1 | (td, C) | S2 | -0.000116 | 0.021071 |
| 11 | y1 | (td, R) | S2 | 0.000220 | 0.020567 |
| 12 | y1 | (td, L) | S2 | 0.000077 | 0.020732 |
| 13 | y1 | (td, R_o) | S2 | 0.000093 | 0.020586 |
| 14 | y1 | (td, p_o) | S2 | 0.000048 | 0.020669 |
| 15 | y1 | (amp, dt) | S2 | -0.005883 | 0.082108 |
| 16 | y1 | (amp, C) | S2 | -0.008970 | 0.085494 |
| 17 | y1 | (amp, R) | S2 | -0.005850 | 0.081559 |
| 18 | y1 | (amp, L) | S2 | -0.005338 | 0.081190 |
| 19 | y1 | (amp, R_o) | S2 | -0.005470 | 0.081701 |
| 20 | y1 | (amp, p_o) | S2 | -0.006961 | 0.082103 |
| 21 | y1 | (dt, C) | S2 | -0.000075 | 0.002877 |
| 22 | y1 | (dt, R) | S2 | 0.000122 | 0.002789 |
| 23 | y1 | (dt, L) | S2 | -0.000084 | 0.002744 |
| 24 | y1 | (dt, R_o) | S2 | -0.000182 | 0.002733 |
| 25 | y1 | (dt, p_o) | S2 | -0.000145 | 0.002738 |
| 26 | y1 | (C, R) | S2 | -0.002829 | 0.028031 |
| 27 | y1 | (C, L) | S2 | -0.002598 | 0.027321 |
| 28 | y1 | (C, R_o) | S2 | -0.002824 | 0.027175 |
| 29 | y1 | (C, p_o) | S2 | -0.003176 | 0.027252 |
| 30 | y1 | (R, L) | S2 | -0.000116 | 0.026164 |
| 31 | y1 | (R, R_o) | S2 | -0.000040 | 0.026326 |
| 32 | y1 | (R, p_o) | S2 | 0.000161 | 0.026226 |
| 33 | y1 | (L, R_o) | S2 | 0.000896 | 0.006832 |
| 34 | y1 | (L, p_o) | S2 | 0.000826 | 0.006798 |
| 35 | y1 | (R_o, p_o) | S2 | 0.000106 | 0.002880 |