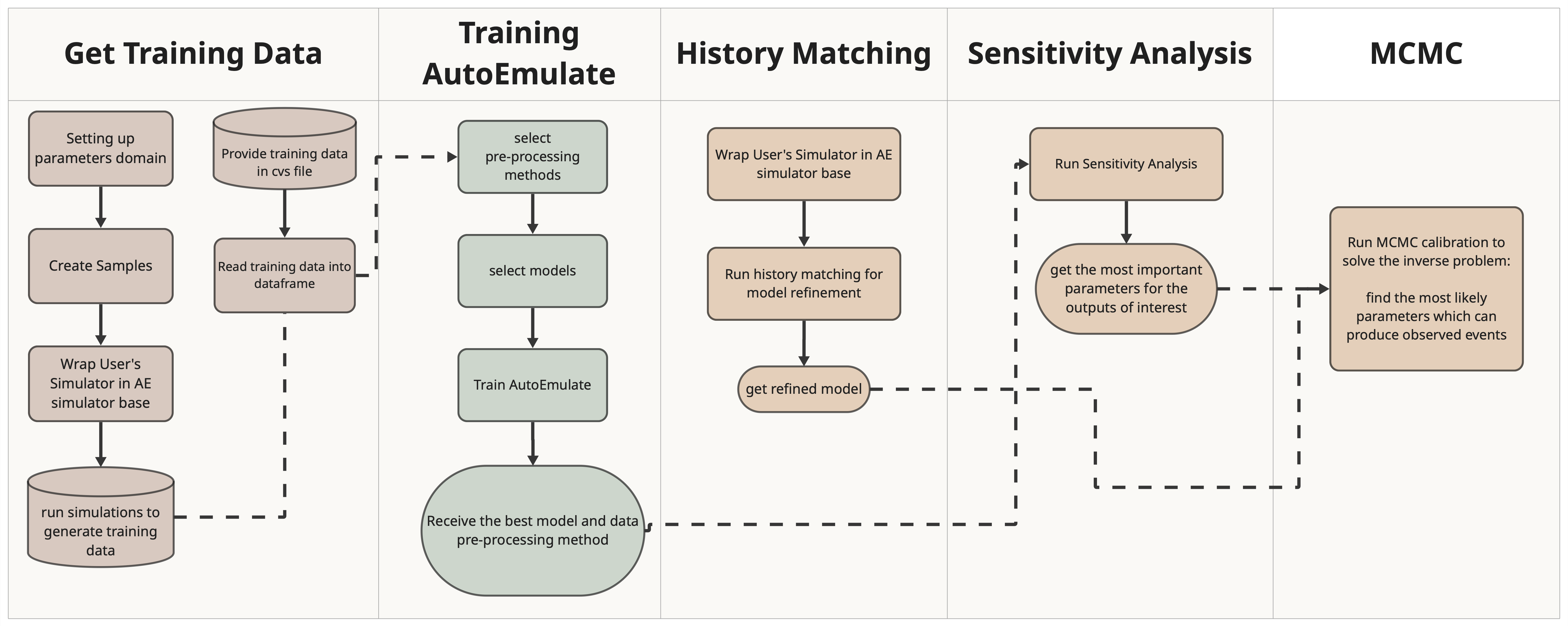
Integrating a user-provided simulator in an end-to-end AutoEmulate workflow#
Overview#
In this workflow we demonstrate the integration of a Cardiovascular simulator, Naghavi Model from ModularCirc in the end-to-end AutoEmulate workflow.
Naghavi model is a 0D (zero-dimensional) computational model of the cardiovascular system, which is used to simulate blood flow and pressure dynamics in the heart and blood vessels.
This demo includes:
Setting up parameter ranges
Creating samples
Running the simulator to generate training data for the emulator
Using AutoEmulate to find the best pre-processing technique and model tailored to the simulation data
Applying history matching to refine the model and enhance parameter ranges
Sensitivity Analysis
Additional dependency requirements#
In this demonstration we are using the Naghavi Model Simulator from ModularCirc library. Therefore, the user needs to install the ModularCirc library in their existing AutoEmulate virtual environemnt as an additional dependency.
# ! pip install git+https://github.com/alan-turing-institute/ModularCirc.git@dev
Workflow#
1 - Create a dictionary called parameters_range which contains the name of the simulator input parameters and their range.#
from autoemulate.simulations.naghavi_cardiac_ModularCirc import extract_parameter_ranges
# Usage example:
parameters_range = extract_parameter_ranges('../data/naghavi_model_parameters.json')
parameters_range
{'ao.r': (120.0, 360.0),
'ao.c': (0.15, 0.44999999999999996),
'art.r': (562.5, 1687.5),
'art.c': (1.5, 4.5),
'ven.r': (4.5, 13.5),
'ven.c': (66.65, 199.95000000000002),
'av.r': (3.0, 9.0),
'mv.r': (2.05, 6.1499999999999995),
'la.E_pas': (0.22, 0.66),
'la.E_act': (0.225, 0.675),
'la.v_ref': (5.0, 15.0),
'la.k_pas': (0.01665, 0.07500000000000001),
'lv.E_pas': (0.5, 1.5),
'lv.E_act': (1.5, 4.5),
'lv.v_ref': (5.0, 15.0),
'lv.k_pas': (0.00999, 0.045)}
2 - Use LatinHypercube method from AutoEmulate to generate initial samples using the parameters range.#
import pandas as pd
import numpy as np
from autoemulate.experimental_design import LatinHypercube
# Generate Latin Hypercube samples
N_samples = 100
lhd = LatinHypercube(list(parameters_range.values()))
sample_array = lhd.sample(N_samples)
sample_df = pd.DataFrame(sample_array, columns=parameters_range.keys())
print("Number of parameters:", sample_df.shape[1], "Number of samples from each parameter:", sample_df.shape[0])
sample_df.head()
Number of parameters: 16 Number of samples from each parameter: 100
| ao.r | ao.c | art.r | art.c | ven.r | ven.c | av.r | mv.r | la.E_pas | la.E_act | la.v_ref | la.k_pas | lv.E_pas | lv.E_act | lv.v_ref | lv.k_pas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 129.040115 | 0.418405 | 1178.419174 | 2.051622 | 11.038884 | 138.908991 | 4.884366 | 3.196254 | 0.264114 | 0.290679 | 11.556454 | 0.042007 | 1.422422 | 2.675922 | 14.422855 | 0.032943 |
| 1 | 150.832341 | 0.161563 | 1234.747526 | 3.762681 | 9.509008 | 171.029031 | 8.739537 | 4.151240 | 0.443777 | 0.611265 | 6.893642 | 0.025606 | 0.710861 | 1.968890 | 13.365385 | 0.033347 |
| 2 | 306.360224 | 0.214942 | 1325.444108 | 4.479567 | 6.452436 | 149.370582 | 3.015869 | 4.565975 | 0.657587 | 0.383106 | 14.479735 | 0.035462 | 0.855721 | 2.292547 | 5.684497 | 0.015966 |
| 3 | 193.826456 | 0.288486 | 1106.496318 | 2.022615 | 5.134734 | 158.998875 | 6.870966 | 4.861239 | 0.374732 | 0.473997 | 13.392921 | 0.057016 | 1.437879 | 1.859862 | 13.416014 | 0.014955 |
| 4 | 247.333174 | 0.330290 | 1008.212629 | 3.113623 | 11.213335 | 119.107338 | 5.734218 | 5.893353 | 0.372833 | 0.328935 | 9.975084 | 0.072922 | 0.846542 | 2.087427 | 12.629324 | 0.035583 |
3 - Wrap your Simulator in the AutoEmulate Simulator Base Class.#

from autoemulate.simulations.naghavi_cardiac_ModularCirc import NaghaviSimulator
# Initialize simulator with specific outputs
simulator = NaghaviSimulator(
parameters_range=parameters_range,
output_variables=['lv.P_i', 'lv.P_o'], # Only the ones you're interested in
n_cycles=300,
dt=0.001,
)
4 - Run the simulator using run_batch_simulations to obtain data for training AutoEmulate.#
results_df = None
run = True
save = False
read = False
if run:
# Run batch simulations with the samples generated in Cell 1
results = simulator.run_batch_simulations(sample_df)
# Convert results to DataFrame for analysis
results_df = pd.DataFrame(results)
if save and results_df is not None:
# Save the results to a CSV file
results_df.to_csv('../data/simulator_results.csv', index=False)
if read:
# Read the results from the CSV file
results_df = pd.read_csv('../data/simulator_results.csv')
results = results_df.to_numpy()
results_df
Note that the first 4 steps can be replaced by having stored the output of your simulation in a file and then reading them in to a dataframe. However the purpose of this article is to demonstrate the use of a User-provided simulator in an end-to-end workflow.
simulator.output_names
Test your simulator with our test function to make sure it is compatible with AutoEmulate pipeline (Feature not provided yet).
# this should be replaced with a test written specically to test the simulator written by the user
# ! pytest ../../tests/test_base_simulator.py
5 - Setup AutoEmulate.#
User should choose from the available target
pre-processingmethods the methods they would like to investigate.User should choose from the available
modelsthemodelsthey would like to investigate.Setup AutoEmulate
import numpy as np
from autoemulate.compare import AutoEmulate
from autoemulate.plotting import _predict_with_optional_std
preprocessing_methods = [{"name" : "PCA", "params" : {"reduced_dim": 2}}]
em = AutoEmulate()
em.setup(sample_df, results, models=["gp"], scale_output = True, reduce_dim_output=True, preprocessing_methods=preprocessing_methods)
6 - Run compare to train AutoEmulate and extract the best model.#
best_model = em.compare()
7 - Examine the summary of cross-validation.#
em.summarise_cv()
best_model
8 - Extract the desired model, run evaluation and refit using the whole dataset.#
You can use the
best_modelselected by AutoEmulateor you can extract the model and pre-processing technique displayed in
em.summarise_cv()
gp = em.get_model('GaussianProcess')
em.evaluate(gp)
# for best model change the line above to:
# em.evaluate(best_model)
gp_final = em.refit(gp)
gp_final
em.plot_eval(gp_final)
9 - Sensitivity Analysis#
Use AutoEmulate to perform sensitivity analysis. This will help identify the parameters that have higher impact on the outputs to narrow down the search space for performing model calibration.
Sobol Interpretation:
\(S_1\) values sum to ≤ 1.0 (exact fraction of variance explained)
\(S_t - S_1\) = interaction effects involving that parameter
Large \(S_t - S_1\) gap indicates strong interactions
Morris Interpretation:
High \(\mu^*\), Low \(\sigma\): Important parameter with linear/monotonic effects
High \(\mu^*\), High \(\sigma\): Important parameter with non-linear effects or interactions
Low \(\mu^*\), High \(\sigma\): Parameter involved in interactions but not individually important
Low \(\mu^*\), Low \(\sigma\): Unimportant parameter
# Extract parameter names and bounds from the dictionary
parameter_names = list(parameters_range.keys())
parameter_bounds = list(parameters_range.values())
# Define the problem dictionary for Sobol sensitivity analysis
problem = {
'num_vars': len(parameter_names),
'names': parameter_names,
'bounds': parameter_bounds
}
si = em.sensitivity_analysis(problem=problem, method='sobol')
si.head()
em.plot_sensitivity_analysis(si)
Refining the Model with Real-World Observations#
To refine our emulator, we need real-world observations to compare against. These observations can come from:
Experimental values from literature
Simulation results from a known reliable parameter set
In this example, we’ll generate our observations by running the simulator at the midpoint of each parameter range, treating these as our “ground truth” values for calibration. Note that in a real world example one can have multiple observations.
# An example of how to define observed data with means and variances from a hypothetical experiment
observations = {
'lv.P_i_min': (5.0, 0.1), # Minimum of minimum LV pressure
'lv.P_i_max': (20.0, 0.1), # Maximum of minimum LV pressure
'lv.P_i_mean': (10.0, 0.1), # Mean of minimum LV pressure
'lv.P_i_range': (15.0, 0.5), # Range of minimum LV pressure
'lv.P_o_min': (1.0, 0.1), # Minimum of maximum LV pressure
'lv.P_o_max': (13.0, 0.1), # Maximum of maximum LV pressure
'lv.P_o_mean': (12.0, 0.1), # Mean of maximum LV pressure
'lv.P_o_range': (20.0, 0.5) # Range of maximum LV pressure
}
# Otherwise, use one forward pass of your simualtion to get the observed data
# Calculate midpoint parameters
midpoint_params = {}
for param_name, (min_val, max_val) in parameters_range.items():
midpoint_params[param_name] = (min_val + max_val) / 2.0
# Run the simulator with midpoint parameters
midpoint_results = simulator.sample_forward(midpoint_params)
# Create observations dictionary
observations = {}
output_names = simulator.output_names
observations = {name: (float(val), max(abs(val) * 0.01, 0.01)) for name, val in zip(output_names, midpoint_results)}
observations
10 - History Matching#
Once you have the final model, running history matching can improve your model. The Implausibility metric is calculated using the following relation for each set of parameter:
\(I_i(\overline{x_0}) = \frac{|z_i - \mathbb{E}(f_i(\overline{x_0}))|}{\sqrt{\text{Var}[z_i - \mathbb{E}(f_i(\overline{x_0}))]}}\) Where if implosibility (\(I_i\)) exceeds a threshhold value, the points will be rulled out. The outcome of history matching are the NORY (Not Ruled Out Yet) and RO (Ruled Out) points.
create a dictionary of your observations, this should match the output names of your simulator
create the history matching object
run history matching
from autoemulate.history_matching import HistoryMatching
# Create history matcher
hm = HistoryMatching(
simulator=simulator,
observations=observations,
threshold=1.0
)
# Run history matching
all_samples, all_impl_scores, emulator = hm.run(
n_waves=50,
n_samples_per_wave=100,
emulator_predict=True,
initial_emulator=gp_final,
)
# Simple NROY extraction - just check the threshold!
threshold = 1.0 # Same threshold used in history matching
# Find samples where ALL outputs have implausibility <= threshold
nroy_mask = np.all(all_impl_scores <= threshold, axis=1)
nroy_indices = np.where(nroy_mask)[0]
nroy_samples = all_samples[nroy_indices]
print(f"Total samples: {len(all_samples)}")
print(f"NROY samples: {len(nroy_samples)}")
print(f"NROY percentage: {len(nroy_samples)/len(all_samples)*100:.1f}%")
from autoemulate.history_matching_dashboard import HistoryMatchingDashboard
dashboard = HistoryMatchingDashboard(
samples=all_samples,
impl_scores=all_impl_scores,
param_names=simulator.param_names,
output_names=simulator.output_names,
)
dashboard.display()
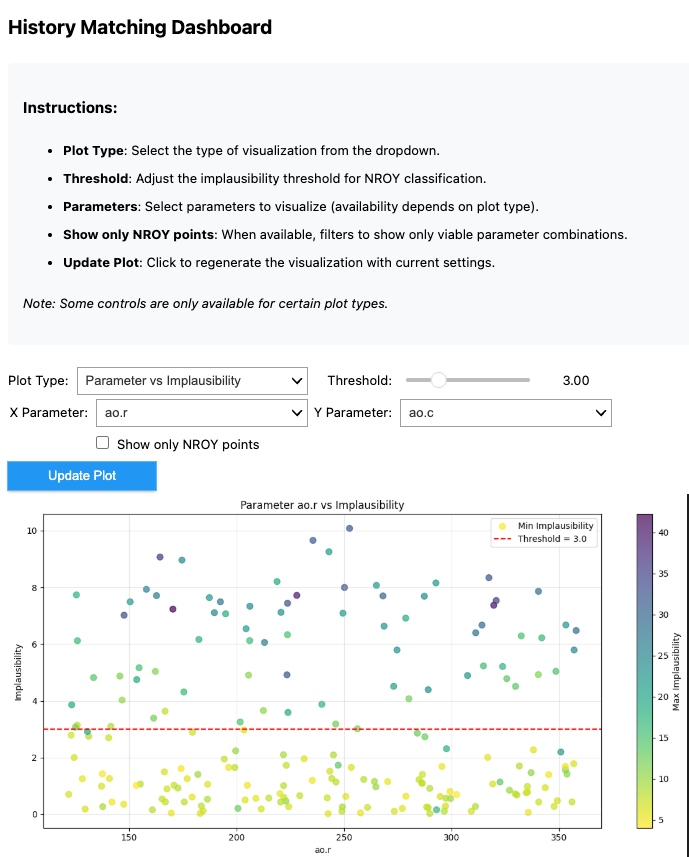 “””
“””
11 - MCMC#
Once you have identified the important parameters through the Sensitivity analysis tool, the MCMC module can return the calibrated parameter values with uncertainty.
The MCMC algorithm tries to find parameter values that match the predictions by the emulator to your observations whilst staying within the parameters_range (priors)
and accounting for uncertainty.
Takes a pre-trained emulator (surrogate model)
Uses sensitivity analysis results to identify the most important parameters
Accepts observations (real data) to calibrate against
Optionally incorporates NROY (Not Ruled Out Yet) samples from prior history matching
Sets up parameter bounds for calibration
from autoemulate.mcmc import MCMCCalibrator
# Define your observations (what you want to match)
# Define observed data with means and variances
# Run calibration
calibrator = MCMCCalibrator(
emulator=gp_final,
sensitivity_results=si,
observations=observations,
parameter_bounds=parameters_range,
nroy_samples=nroy_samples,
nroy_indices=nroy_indices,
all_samples=all_samples,
top_n_params=3 # Calibrate top 5 most sensitive parameters
)
results = calibrator.run_mcmc(num_samples=100, warmup_steps=10)
# Get calibrated parameter values
calibrated_params = calibrator.get_calibrated_parameters()
calibrated_params
from autoemulate.mcmc_dashboard import MCMCVisualizationDashboard
dashboard = MCMCVisualizationDashboard(calibrator)
dashboard.display()
Footnote: Testing the dashboard#
Sometimes it is hard to know, if the results we are seeing is because the code is not working, or our simulation results are more interesting than we expected. Here is a little test dataset which tests the dashboard, so that you can see how the plots are supposed to look liek and what they shouldf show
# Create a test sample with KNOWN NROY regions
test_samples = np.array([[x, y] for x in np.linspace(0,1,100)
for y in np.linspace(0,1,100)])
test_scores = (abs(test_samples[:, 0]-0.5)+abs(test_samples[:, 1]-0.5)).reshape(-1, 1)
# Should show a clear diagonal pattern
test_dash = HistoryMatchingDashboard(
samples=test_samples,
impl_scores=test_scores,
param_names=["p1", "p2"],
output_names=["out1"],
threshold=0.7 # ~50% of points should be NROY
)
#test_dash.display()